< 큐레이션 및 알고리즘이 만든 함정?...>

- 어느순간 부터 내가 좋아서 본 건지, 계속 보여서 좋아진 건지 모르겠는 부분이 생기기 시작한 시대가 되어버렸습니다.
- 인스타 피드를 넘기면 항상 보게 되는 ‘그런’ 이미지들이 있다. 창이 많은 무채색 건물, 선명한 하늘, 검정색 니트나 어두운 립을 바른 사람, 정갈하게 정리된 책상 위에 우유빛 커피 한 잔...
- 나는 좋아한다고 말한 적 없는데, 어느 순간 이게 ‘나의 취향’이 되어 있었다고 볼 수 있습니다. 우리는 요즘 이렇게 ‘내가 고른 것’이라 착각하는 것들로 하루를 살아가게 되고 있는 것 같습니다.
- 그건 넷플릭스가 보여준 콘텐츠일 수도 있고, 유튜브가 추천해준 영상, 쇼핑 앱에서 뜨는 옷 스타일, 혹은 새로 생긴 카페의 분위기까지... 좋아함과 노출의 경계는 점점 흐려지고 있는 것입니다.
< 진짜 내가 좋아하는 걸까? 아니면 그냥, 익숙해진 것뿐일까?...>
- 이것은 우리만의 이야기가 아닙니다. 데이터에서도 이런 부분들은 너무나 흔하게 발견되고 있습니다.
1. 미국의 음악 스트리밍 서비스 Pandora는 놀라운 데이터를 발견했습니다.

- “내가 좋아하는 음악 = 가장 많이 들은 음악”이 아니라, “자주 들려준 음악 = 결국 좋아지게 된 음악”인 경우가 많았다는 부분입니다.
- 그리고 이런 문장이 보고서에 적혀 있었습니다. “우리는 사용자의 취향을 예측한 게 아니라, 사용자의 취향을 조성했다.” 라는 내용이었죠
2. 넷플릭스는 사용자 성향에 맞춰 썸네일을 바꿔 보여주는 알고리즘을 쓰고 있습니다.

- 같은 영화라도, 로맨스를 좋아하는 사람에게는 키스신을 보여주고, 스릴러를 좋아하는 사람에게는 어두운 장면을 보여주곤 합니다.
- 당연히 클릭률은 높아졌습니다. 콘텐츠의 실제 내용보다 썸네일이 클릭률을 결정했다고 볼 수 있습니다.
- 어떤 사람은 ‘러브스토리’라고 믿고 재생했지만, 정작 내용은 사이코 스릴러였던 것 입니다. 하지만 아이러니 하게도 끝까지 보게 되는 경우가 더욱 많아졌습니다. ‘보고 싶었던 건 아니지만, 보고 나니 괜찮은’ 이 모호한 감정은, 결국 다시 추천 알고리즘을 정교하게 만들어 버리곤 합니다..
- 하지만 사람들은 묻기 시작했죠. “내가 이걸 정말 보고 싶었던 건가?”
3. TikTok – “내가 좋아하는 게 뭔지 모르겠어요”

- TikTok은 전통적인 취향 기반 추천이 아닌, 반사적 행동 기반 알고리즘을 통해 콘텐츠를 선별합니다.
- 즉, 사용자가 좋아요를 눌렀는지가 아니라, 몇 초 머물렀는지, 스크롤 속도가 느려졌는지, 영상을 반복 재생했는지 같은 미세한 ‘행동 데이터’가 피드 구성을 좌우합니다.
- 이 알고리즘의 무서운 점은, 사용자가 무엇을 좋아하는지 묻지 않고, 단지 무의식적으로 멈춘 시간을 근거로 콘텐츠를 계속 던진다는 점입니다.
- 그 결과, 수많은 사용자들이 이런 말을 하기 시작했습니다. “계속 보게 되긴 하는데, 다 보고 나면 뭔가 허무해요." “좋아해서 본 게 아니라, 그냥 계속 보여서 본 것 같아요.” 라는 반응이 나타나곤 합니다.
- 실제로 틱톡 중독은 취향의 정체성을 흐리게 만든다는 지적을 받고 있습니다. “나는 뭘 좋아하더라?“라는 자아 회의가, 15초짜리 짧은 영상 속에서 점점 커지고 있는 것입니다.
4. Steam – “추천보다 랜덤이 더 설렌다”

- 세계 최대의 게임 플랫폼 Steam은 오랜 시간 개인화 추천 알고리즘을 발전시켜 왔습니다.
- 유저의 플레이 기록, 장르 선호, 친구들의 활동 내역을 반영해 “너라면 이 게임을 좋아할 거야”라는 추천을 매일 제공합니다. 하지만 아이러니하게도, 가장 유저의 관심과 전환율이 높았던 건 추천이 아닌 ‘랜덤 할인’ 이벤트였습니다.
- Steam은 시즌별로 ‘랜덤 딜’ 이벤트를 진행하며, 유저가 전혀 예상하지 못한 타이틀을 특정 시간대에만 할인하는 방식으로 운영했습니다. 이 이벤트에서 클릭률은 맞춤 추천 대비 2배 이상 높았고, 구매 전환율도 상승했습니다.
- 유저들은 이렇게 말합니다. “추천은 너무 비슷한 게임만 보여줘서 질려요." , “랜덤 할인 덕분에 평소 안 하던 게임을 해보게 됐어요.” 라는 반응들을 보이곤 합니다.
- 즉, 예측 가능한 정확함은 흥미를 떨어뜨리고, 우연의 요소는 오히려 탐험의 재미를 선사하게 된 것입니다.
5. Goodreads – “누가 읽었느냐가 더 중요해”
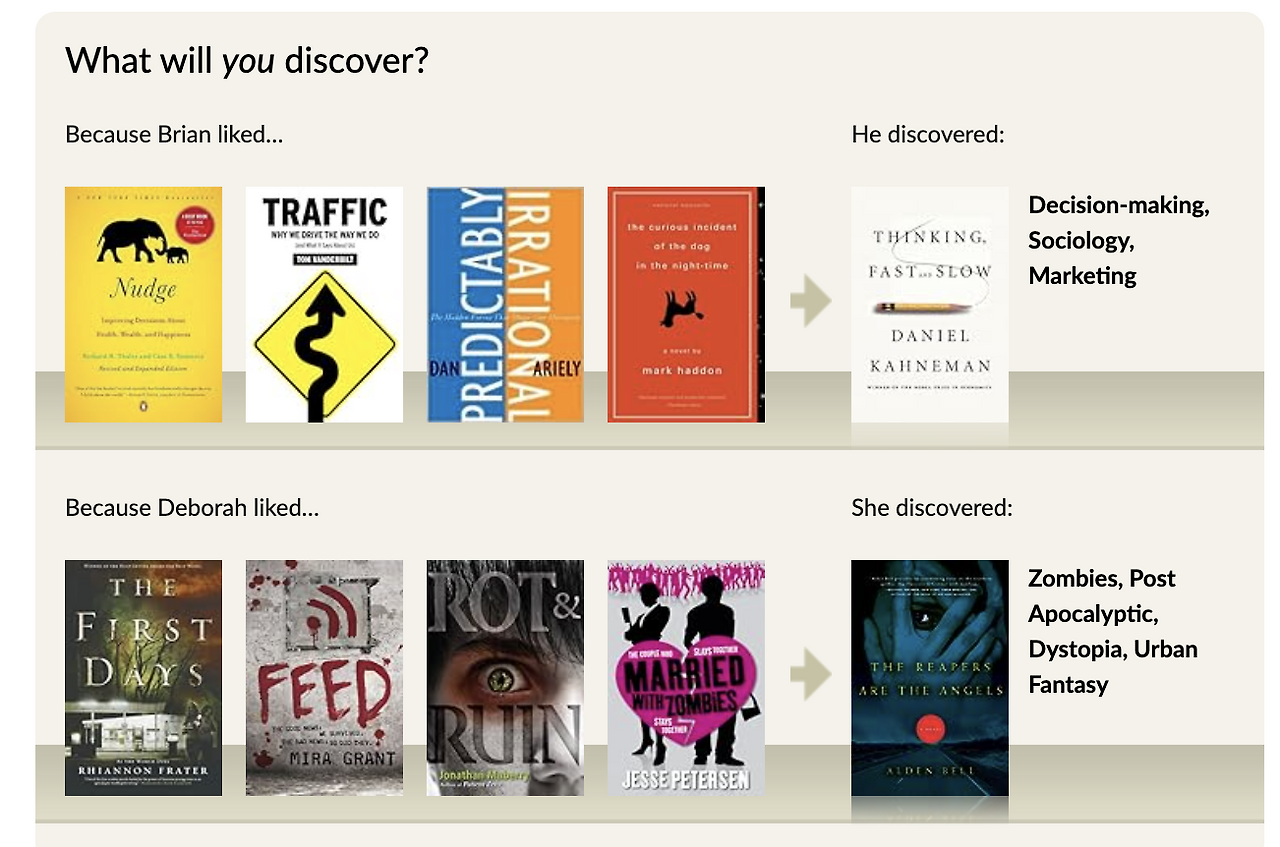
- 책 추천 플랫폼 Goodreads는 아마존이 인수한 뒤로 AI 기반 추천 시스템을 강화해왔습니다. 유저의 평점, 선호 장르, 과거 독서 기록을 바탕으로 자동화된 도서 추천을 제공합니다.
- 하지만 Goodreads 사용자들이 실제로 신뢰하는 건 알고리즘이 아닌 ‘사람’, 특히 ‘친구’의 책장이었습니다. 연구에 따르면 Goodreads 유저는 책의 장르나 평점보다 “내 친구가 이 책을 왜 골랐는지”, “나와 비슷한 취향의 사람이 읽고 어떻게 느꼈는지” 를 더 중시하며 독서 선택을 합니다.
- 알고리즘은 “비슷한 책”을 보여주지만, 친구는 “내가 몰랐던 책”을 알려줍니다. 그리고 그 차이는 매우 큽니다. 많은 유저들이 이렇게 리뷰했습니다. “추천 책 리스트보다 친구가 남긴 한 줄 서평이 더 와닿았어요.”, “그 친구가 읽었기에, 나도 읽고 싶어졌죠.” 반응들을 보이곤 합니다.
- 이처럼 ‘정확함’ 보다 ‘연결’과 ‘신뢰’가 더 강력한 큐레이션이 될 수 있음을 보여주는 사례입니다.
< 추천 보다는 랜덤함으로 이동되는 트렌드?...>

- 이건 단지 콘텐츠 이야기만은 아닙니다. 이커머스, 패션, 음식, 심지어 여행지까지 우리가 좋아한다고 믿는 많은 것들이 실은 알고리즘이 쥐여준 ‘맞춤형 취향’에 불과할지도 모른다고 볼 수 있습니다.
✅ 실제로 독일 베를린 기반의 커머스 스타트업 Modomoto는 개인의 취향을 AI로 분석해 스타일리스트가 옷을 큐레이션해주는 서비스였는데, 몇 년간 성장하다가 2020년 문을 닫았습니다.
❌ 사용자 리뷰에서 가장 많이 나온 말은 “매번 비슷한 옷이 와서 지겨웠다”였습니다. 한 마디로, ‘정확한 추천’이 결국은 ‘예상 가능한 지루함’이 된 셈이라고도 볼 수 있습니다.
⁉️ 그리고 흥미롭게도, 요즘 유럽과 일본에서 주목받는 커머스 앱들은 다시 ‘랜덤박스’를 전면에 내세우는 것을 볼 수 있습니다. 정확한 취향 분석보다, 예상 못한 무작위성과 놀람을 주는 쪽으로 트렌드가 이동 중인셈 입니다.
⭕️ 대표적으로 프랑스의 ‘Digger’라는 신생 이커머스 앱은 AI 추천을 최소화하고, 매일 10개씩 전혀 다른 스타일의 제품을 무작위로 보여주고 있습니다. 그리고 사용자에게 이런 질문을 던지고는 합니다. “오늘은 누구의 취향이 되고 싶나요?”
❗️놀랍게도 이 앱의 평균 체류 시간은 개인화 기반 커머스 앱보다 1.7배 길었습니다.
< 나도 나를 모르는데?...>
- 위에 랜덤사례는 “내 취향”이 아닌 “모르는 취향”을 탐험하는 데 더 오래 머무는 것이라고 볼 수 있습니다.
- 결국 내가 고른 것 같지만, 실은 알고리즘이 정해준 인생이 아닐까. 추천에 익숙해질수록 내가 뭘 원하는지도 모르게 되는 딜레마에 빠지게 되는 현상이 발생하는 것 입니다.
- 좋아해서 본 건지, 보여서 좋아진 건지. 그 질문에 확신을 갖기 위해서 우리는 가끔 의도적인 무작위성이 필요하게 된 것일 수도 있습닌다. 내 취향이 어딘가에 정해져 있는 게 아니라, 여전히 변하고 있는 과정 속에 있다는 걸 믿기 위해서 말이죠
✓ 마치며
- 가끔은 일부러 낯선 브랜드를 검색해봅니다. 팔로우 하지 않은 계정을 본다. 한 번도 들어본 적 없는 플레이리스트를 랜덤 재생하기도 해보고요. 그렇게라도 ‘진짜 내 취향’과 다시 만나고 싶어서 인 것 같습니다.
- 우리는 오늘도 무언가를 선택하고 있지만, 어쩌면 가장 큰 선택은 '정확한 것’보다 ‘낯선 것’을 택하는 용기인지도 모르니까요.
