
대부분의 기업은 성장을 위해 더 많은 '아이디어'를 원하지만, 정작 성장을 가로막는 병목은 아이디어의 부족이 아니라 어떤 아이디어가 진짜 수익을 가져다줄지 판별하지 못하는 검증 시스템의 부재에 있습니다. 가설 목록은 잔뜩 쌓여있지만, 실제 데이터를 열어보면 0.04~0.09 사이의 P-value를 오가며 아무런 결론도 내리지 못하는 '애매한 실험'만 반복되는 경우가 허다합니다. 결국 팀은 다시 직관에 의존하는 의사결정으로 회귀하고, 실험은 그저 '해봤다'는 기록용 이벤트로 전락합니다.

출처: A/B Testing: The Science of Not Fooling Yourself - Neweconomies
마이크로소프트와 구글의 가설실험 시스템을 구축한 론 코하비(Ronny Kohavi)는 대부분의 아이디어는 실패하며, 심지어 고도로 숙련된 팀이 세운 가설조차 70~90%는 중립적이거나 부정적인 결과를 낸다고 경고합니다. 그는 아이디어의 화려함보다 그 아이디어를 검증하는 시스템의 신뢰성(Trustworthiness)이 성장의 속도를 결정한다고 강조합니다. 즉, 성장하는 조직은 '틀릴 수밖에 없는 가설'을 얼마나 빠르고 적은 비용으로 걸러내어 다음 단계로 넘어가느냐에 자원을 집중합니다. 이것이 바로 가설실험 설계가 통계학의 영역을 넘어 비즈니스 리소스 배분의 최적화 영역인 이유입니다.
이번 글에선 지난 실험하는 조직이 빠르게 성장하는 법: AB TEST(1)에서 다뤘던 가설을 실제 비즈니스 임팩트로 전환하기 위해 필요한 실무 방법론과 스포티파이(Spotify)의 리스크 관리 프레임워크를 깊이 있게 살펴보겠습니다.
1. 가설 평가 프레임워크: 실험의 우선순위 설정법
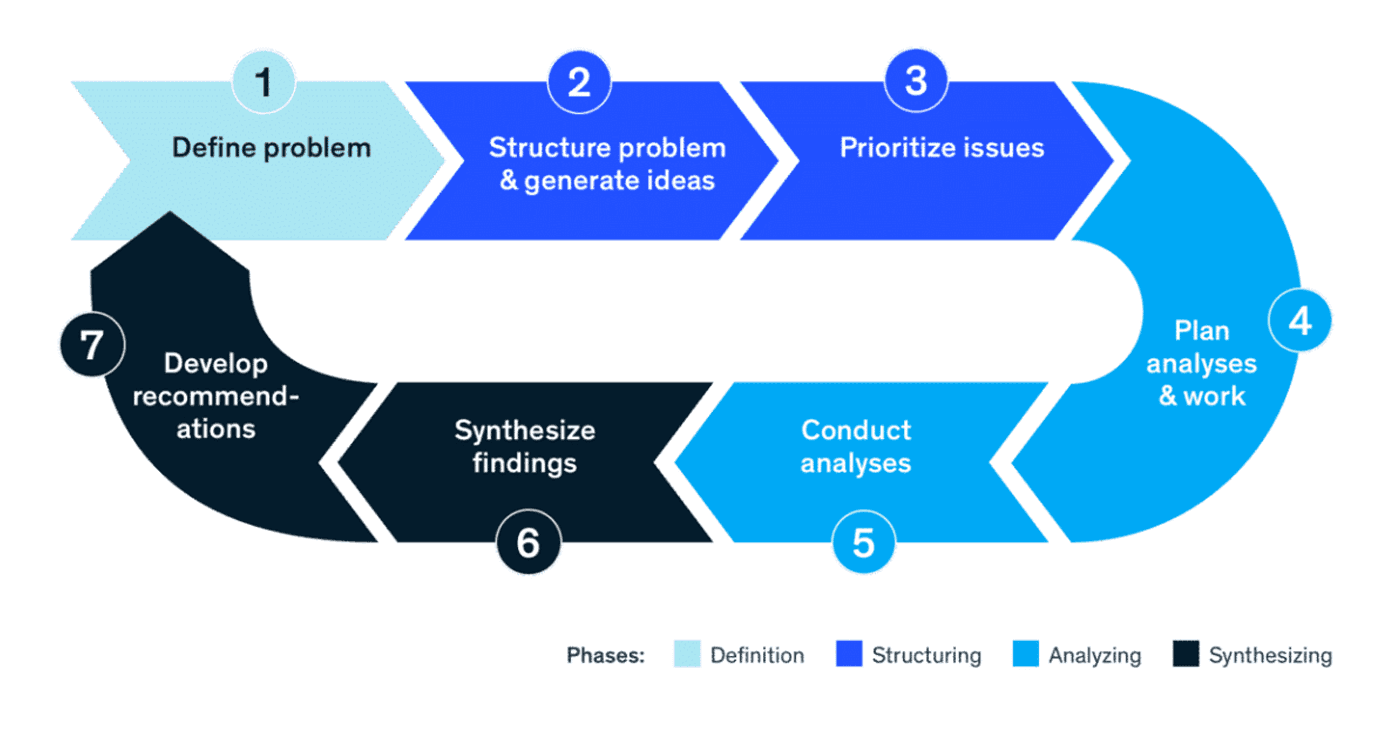
출처: 7-Step Hypothesis-Led Problem
가설 수립은 단순한 추측을 넘어서 비즈니스의 인과관계를 증명하는 설계도에 가깝습니다. 문제는 실무 상황에서는 개발 리소스와 시간 제약 등 한 번에 실행할 수 있는 실험의 수는 제한적인데, 실험하고 싶은 가설은 그보다 항상 많다는 점입니다. 결국 성장을 가르는 것은 ‘얼마나 많은 가설을 생각해냈는가’가 아니라, 그중 어떤 가설을 먼저 검증했는가입니다.
여기서 필요한 것이 바로 가설 평가 프레임워크입니다. 여러 기업의 실험 로그를 들여다보면, 팀들이 실제로 가설의 가치를 판단할 때 결국 세 가지 질문으로 수렴하는 경우가 많습니다.
- 이 가설은 사람의 의사결정 패턴(심리)을 제대로 반영하고 있는가?
- 이 가설은 실제 데이터로 확인된 병목에서 출발했는가?
- 이 가설이 맞았을 때, 리소스 대비 임팩트가 충분히 큰가?
실무에서는 이 세 축을 기준으로 대부분의 가설을 서로 겹치지 않게, 빠짐없이(MECE) 비교할 수 있습니다. 아래 표는 이 세 축을 정리한 것입니다.
1.1. 가설 평가의 세 가지 분류 기준
| 분류 | 가설 선정 기준 | 우선순위 결정에 주는 시사점 |
|---|---|---|
| 심리 기반 | 손실 회피, 사회적 증거, 긴급성 등 검증된 행동 심리학 원칙에 기대고 있는가 | 논리적 설득력, 재현성, 다른 채널·페르소나에 확장할 수 있는지 |
| 데이터 기반 | 실제 이탈 지점·행동 로그·코호트 분석에서 나온 문제인가 | 지금 당장 해결해야 할 병목인지, LTV·Retention에 직접 연결되는지 |
| 임팩트 기반 | 구현 난이도 대비 성장 잠재력이 충분히 큰가 | 동일 리소스로 얻을 수 있는 매출·전환·리텐션 개선 폭(ROI) |
이 프레임워크의 목적은 심리 기반 가설과 데이터 기반 가설 중 누가 더 우월한지를 따지는 것이 아닙니다. 심리적으로 설득력이 있으면서도, 실제 데이터에서 확인된 병목을 겨냥하고, 그 결과 비즈니스 임팩트도 큰 가설을 1순위로 빠르게 추리는 것이 핵심입니다. 이제 각 축을 하나씩, 실제 실무에서 어떻게 활용할 수 있는지 살펴보겠습니다.
1.2. 심리 기반: 왜 이 가설이 사람을 움직일 것인가

출처: Behavioral Perspective - The Decision Lab
모든 숫자는 결국 사람의 행동에서 비롯됩니다. 따라서 ‘이 가설이 왜 통할 것인가?’에 대해 행동 심리학 관점의 설명을 근거로 접근한다면, 실험의 성공 확률도 높아지고 실패했을 때의 학습 가치도 커집니다. 숫자만 남는 실험이 아니라, ‘고객이 왜 이렇게 반응했는가’에 대한 이해가 함께 쌓이기 때문입니다.
마케팅·프로덕트 실무에서 특히 자주 쓰이는 네 가지 원칙을 예로 들어보겠습니다.
- 손실 회피(Loss Aversion)
- 심리적 가격 책정(Psychological Pricing)
- 사회적 증거(Social Proof)
- 긴급성·희소성(Scarcity & Urgency)
이처럼 심리 원칙이 뒷받침된 가설은 성공했을 때는 “왜 잘 됐는지”를 설명하기 쉽고, 실패했을 때는 “심리 가정이 틀렸는지, 적용 대상이 달랐는지”를 분해해 볼 수 있습니다. 즉, 단순히 “해봤더니 안 됐다”에서 끝나는 것이 아니라, 심리 모델 자체를 업데이트하는 실험으로 만들 수 있습니다.
1.3. 데이터 기반 의사결정: ‘느낌’이 아닌 병목에서 출발하라
출처: A/B Testing Essentials: Strategies, Metrics, and AI - Devtodev
아무리 심리적으로 매력적인 가설이라도, 실제 병목과 상관없는 지점을 때리고 있다면 성장에는 거의 기여하지 못합니다. 그래서 두 번째 축은 “이 가설이 근본적인 문제를 기반으로 도출되었는가?”입니다. 실무에서 자주 보이는 잘못된 패턴은 다음과 같습니다.
| 추상적 가설 (직관형) | 구체적 가설 (데이터 기반) |
|---|---|
| 고객들이 더 많은 기능을 원할 것 같다. | 가입 후 7일 내 대시보드 미사용 유저의 30일 이탈률이 80%다. 온보딩에서 대시보드 최초 진입을 유도하면 이탈률을 낮출 수 있을 것이다. |
| 가격이 너무 높은 것 같다. | 경쟁사 평균 가격은 월 $99, 우리는 $149다. 가격 민감도 분석 결과 20% 인하 시 DAU 기준 15~20% 수요 증가가 예상된다. |
| UI가 좀 복잡한 느낌이다. | 신규 유저 인터뷰에서 43%가 첫 화면에서 ‘Next’ 버튼을 찾지 못했다고 답했다. CTA 위치와 크기를 수정하면 온보딩 완료율이 개선될 것이다. |
좋은 가설은 느낌이 아니라, 누가·어디서·어떻게 이탈하고 있는지를 명시합니다. 이를 위해 최소한 다음 네 단계를 파악해 보는 것을 권장드립니다.
- 이탈 분석 – 퍼널 상 어느 단계에서 사용자가 가장 많이 이탈하는지 본다.
- 세그먼트 분석 – 신규/기존, 채널별, 디바이스별, 국가별로 이탈 패턴이 어떻게 다른지 본다.
- 행동 패턴 분석 – 이탈 직전 마지막 행동, 사용 기능 순서, 세션 길이 등에서 공통된 패턴을 찾는다.
- 근본 원인 가설 – 정성 조사(인터뷰, 설문), 세션 리플레이, 과거 AB테스트 결과를 함께 보며 “왜”를 뽑아낸다.
이 과정을 거친 뒤, 다시 심리 축을 가져와 “이 병목 구간에서는 어떤 심리 트리거가 유효할까?”를 적용하면 데이터와 심리가 결합된 가설이 됩니다. 즉, ‘어디서/누가/무엇 때문에’를 데이터로 규정한 상태에서, “어떤 심리 레버를 당길 것인가”를 설계하는 것이 실험 성공률을 가장 현실적으로 끌어올리는 방법입니다.
1.4. ICE Scoring 프레임워크
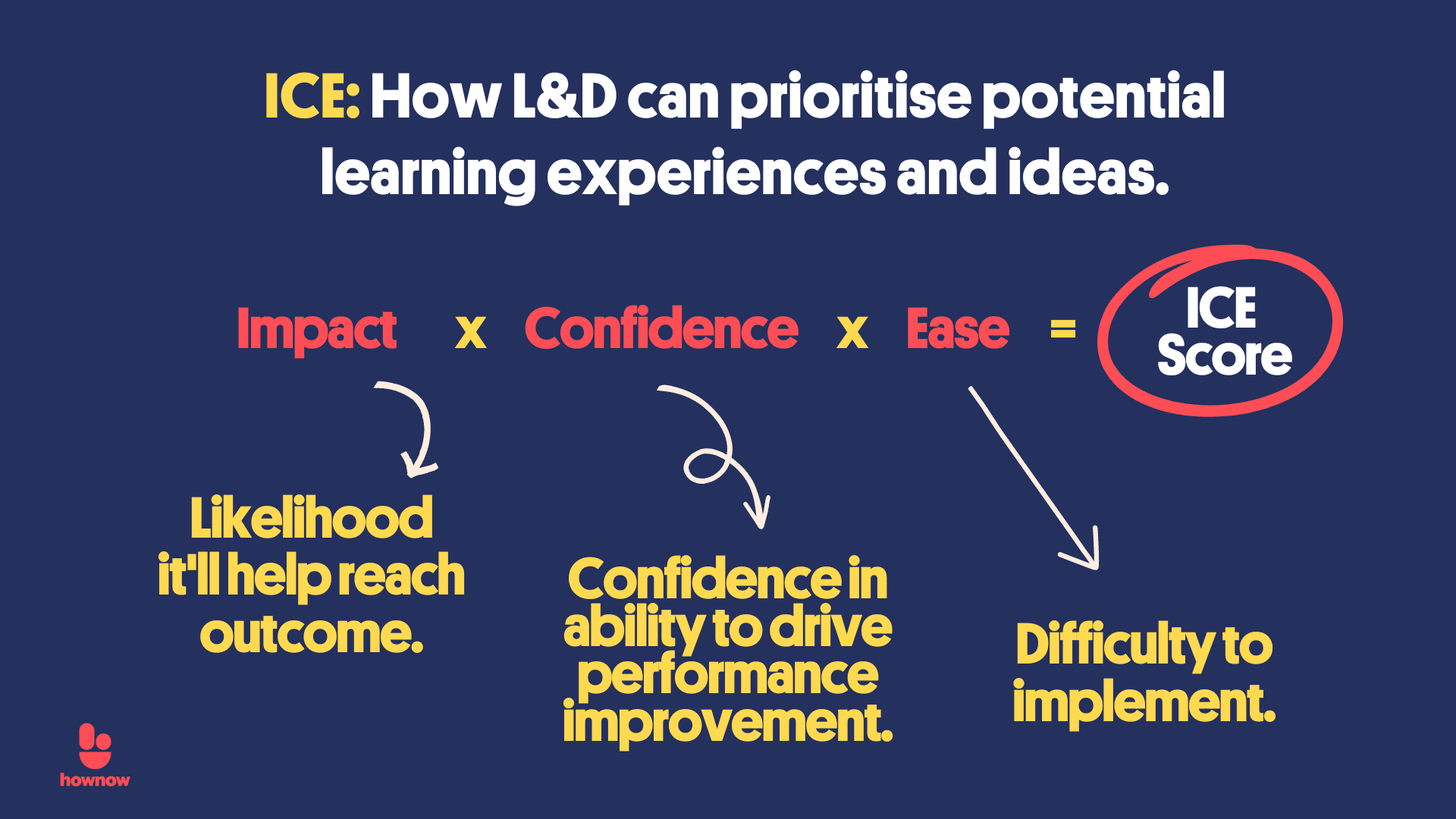
출처: The ICE Framework: L&D's Impact, Confidence And Ease Idea Scoring System
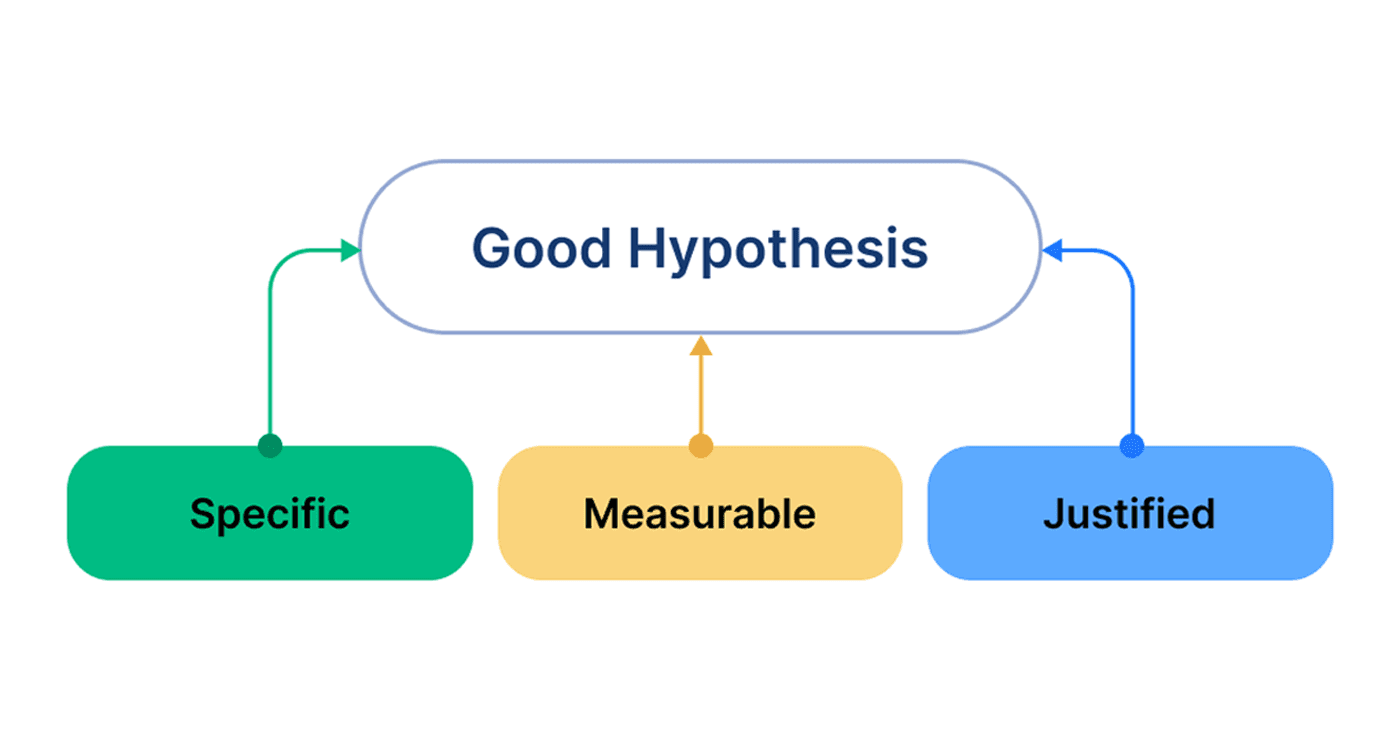
마지막 축은 “이 가설이 맞았을 때 정말로 의미 있는 차이를 만들 수 있는가?”입니다. 여기서 실무에서 널리 쓰이는 도구가 ICE Scring 프레임워크입니다. ICE는 세 가지 요소의 약자입니다. ICE Score 계산법은 Impact × Confidence × Ease 세 가지 요소를 곱한 값으로 점수를 매깁니다.
참고: 필요에 따라 곱셈(Impact x Confidence x Ease) 대신 평균값((I+C+E)/3)을 사용하여 점수를 계산하기도 합니다.
각 항목에 1~10점으로 점수를 주고 아래와 같이 계산을 진행합니다. 이를 토대로 가설을 선정할 때는 구현 난이도 대비 기대 효과(ROI)를 최우선으로 고려하여 리소스를 배분해야 합니다.
| 요소 | 설명 | 점수 방식 |
|---|---|---|
| Impact (임팩트) | 구현 시 기대되는 비즈니스 성과 (전환율 증가%, 수익 증가액 등) | 1-10점 |
| Confidence (확실성) | 이 가설이 실제로 작동할 확률 (심리학적 근거, 데이터 신뢰도) | 1-10점 |
| Ease (용이성) | 구현의 난이도 (개발 시간, 기술적 복잡도) | 1-10점 |
ICE Scoring 예시
| 가설 | Impact | Confidence | Ease | Score | 우선순위 |
|---|---|---|---|---|---|
| 버튼 색상 변경 (빨강 → 초록) | 2 | 6 | 9 | 108 | ⭐⭐ |
| 가격 페이지 레이아웃 변경 | 6 | 8 | 8 | 384 | ⭐⭐⭐⭐⭐ |
| 신규 기능 추가 (고급 분석) | 7 | 7 | 2 | 98 | ⭐ |
| 온보딩 강화 (동영상 가이드) | 8 | 8 | 5 | 320 | ⭐⭐⭐⭐ |
점수가 높을수록 같은 리소스로 더 큰 성장과 학습을 낼 수 있는 가설이라는 뜻입니다. ICE 프레임워크의 특징은 복잡한 데이터 없이도 빠르게 우선순위를 결정할 수 있습니다. 그리고 감보다는 데이터와 논리(Confidence)를 바탕으로 점수를 매기도록 유도하여 주관성을 배제한 가설 선정이 가능합니다.
가설을 선정할 때는 구현 난이도 대비 기대 효과인 비즈니스 임팩트를 최우선으로 고려하여 리소스를 배분해야 합니다. 버튼 색상 변경과 같은 낮은 임팩트의 실험보다는 가격 정책이나 가치 제안(Value Proposition) 변경처럼 비약적인 성장을 가져올 수 있는 가설에 집중하는 것이 효율적입니다. 조직은 빠른 승리(Quick Win)가 가능한 가설부터 시작하여 점차 임팩트가 큰 전략적 가설로 실험 범위를 확대해야 합니다.
높은 ICE Score 순으로 실행하면, 동일한 시간과 자원으로도 더 높은 성장을 이룰 수 있습니다. 이렇게 선별·정렬된 가설들 위에서, 다음 단계인 MDE(최소 감지 효과), 표본 크기, 가드레일 지표 설계를 올려 놓으면 비즈니스의 성장을 견인하는 가설 실험 AB테스트를 설계할 수 있게 됩니다.
2. AB테스트 실무: 정확한 검증 설계가 성장 속도를 결정한다
출처: How to Conduct A/B Testing? | FlowMapp design blog
가설이 명확해졌다면, 이제 이를 정교하게 검증하는 설계가 필요합니다. AB TEST(1)에서 수립한 가설을 이제 통계적 엄격함으로 검증하되, 이를 비즈니스 맥락으로 번역하는 능력이 핵심입니다.
가설이 잘 정리되었다면, 그다음은 ‘얼마나 많이 실험하느냐’가 아니라 ‘얼마나 잘 설계된 실험을 하느냐’의 문제로 넘어갑니다. 같은 가설이라도 표본 크기와 기간, MDE, 지표 구조(성공 지표·가드레일 지표) 설계에 따라 전혀 다른 결론이 나옵니다.
이 구간에서 실험의 질을 가르는 핵심 개념이 바로 표본 크기와 p-value, MDE입니다.
2.1. 표본 크기 계산: 충분히 큰 숫자의 의미
AB테스트를 할 때 가장 먼저 결정해야 할 것은 얼마나 많은 사용자를 테스트해야 하는가입니다. 이것을 표본 크기(Sample Size)라고 부릅니다.
많은 팀이 ‘한 달 정도면 되지 않을까?, “대충 1,000명씩은 들어와야지’처럼 감으로 결정하지만, 이 선택은 곧 실험의 신뢰도와 직결됩니다. 너무 적게 모으면 실제로 효과가 있어도 못 보고(거짓 음성), 너무 느슨하게 멈추면 우연한 차이를 성공으로 오인하기 쉽습니다(거짓 양성).
표본 크기를 결정하는 네 가지 요소
| 요소 | 의미 | 비즈니스 영향 |
|---|---|---|
| Baseline Conversion Rate (기존 전환율) | 현재 A의 전환율 (예: 10%) | 기존 수치가 높을수록 더 큰 표본 필요 |
| Minimum Detectable Effect (MDE) | 우리가 의미 있다고 판단할 개선치 (예: 10% → 11%, 즉 1%p) | 미세한 개선을 원할수록 더 큰 표본 필요 |
| Significance Level (α) | 우연일 확률을 얼마까지 허용할 것인가 (보통 5%) | 더 엄격할수록 더 큰 표본 필요 |
| Statistical Power (1-β) | 실제 효과가 있을 때 이를 찾을 확률 (보통 80%) | 더 높은 신뢰도를 원할수록 더 큰 표본 필요 |
기존 전환율(Baseline), 우리가 의미 있다고 보는 최소 변화량(MDE), 우연을 얼마나 허용할지(유의수준 α), 그리고 실제 효과를 놓치지 않을 확률(검정력, Power)입니다. 기존 전환율이 높을수록, 그리고 감지하고 싶은 변화(MDE)가 작을수록 더 많은 표본이 필요합니다. 유의수준을 엄격하게(예: 1%) 잡으면 거짓 성공은 줄지만, 그만큼 더 많은 사용자와 시간이 필요합니다. 반대로 검정력을 낮추면(예: 60%) 표본은 줄어들지만 실제로 좋은 아이디어를 놓칠 가능성이 커집니다. 결국 표본 크기는 ‘우리가 어떤 수준의 리스크를 감수할 것인가’에 대한 비즈니스 선택이기도 합니다.
예) 표본크기 실무 사례
온보딩 페이지의 CTA 버튼을 개선한다고 합시다.
- 현재 클릭율: 15%
- 예상 개선: 2%p (15% → 17%)
- 유의 수준: 5%, 검정력: 80%
→ 필요한 표본: 약 4,000명 (A/B 각각 2,000명)
만약 2,000명만 테스트했다면? 실제로 효과가 2%p 있어도 통계적으로 유의미하지 않다고 판정될 확률이 높습니다.
2.2. P-value > 0.05: 실패가 아닌 의사결정의 새로운 시작
출처: In defence of the P-value | Scientist Sees Squirrel
가설 설계가 끝나고 실험 결과가 나오면 가장 먼저 마주하는 숫자가 p-value입니다. 흔히 0.05보다 작으면 성공, 크면 실패라고 단정 짓곤 하지만 p-value의 본질은 성공 확률이 아니라 우연히 발생했을 가능성을 측정하는 도구입니다. 예를 들어 p-value가 0.03이라면 A와 B에 차이가 없는데 이런 결과가 우연히 나왔을 확률이 3%라는 뜻입니다. 반대로 0.05를 넘었다는 것은 두 안의 우열을 가릴 만큼 증거가 충분하지 않거나 진짜로 차이가 없다는 신호로 해석해야 합니다.
실무에서 p-value 자체보다 중요한 것은 표본 크기(Sample Size)와 함께 읽는 관점입니다. 설계 단계에서 정한 표본 수를 다 채웠음에도 p-value가 높다면 그 가설은 비즈니스적으로 효과가 없음을 의미합니다. 반면 표본이 부족한 상태에서 p-value가 높은 것은 차이가 없다는 결론이 아니라 아직 알 수 없다는 뜻입니다. 따라서 반드시 설계된 표본과 기간을 모두 채운 뒤에 p-value를 해석해야 의사결정의 오류를 줄일 수 있습니다.
업계의 A/B 테스트 중 약 70~80%는 지표 변화가 없는 Flat으로 결론납니다. 통계적 유의성을 확보하지 못했을 때 실무자가 취해야 할 데이터 기반 대응 전략은 크게 네 가지 단계로 요약됩니다.
- 표본 크기와 실험 기간 재확인: 실험 설계 당시 계산했던 최소 표본 수를 모두 채웠는지 점검해야 합니다. 데이터가 충분히 쌓이지 않아 차이가 드러나지 않았을 수 있습니다. 충분한 표본이 모였음에도 p-value가 0.05를 넘는다면 효과가 너무 미미하여 비즈니스적 가치가 없는 것으로 판단하고 종료하는 것이 효율적입니다.
- 세그먼트 분석(Post-hoc Segmentation): 전체 사용자에게는 효과가 없었지만 특정 그룹에서는 반응이 있었을지 모릅니다. 신규 유입자, 모바일 유저, 특정 광고 채널 유입자 등으로 데이터를 쪼개서 살펴보십시오. 여기서 발견한 인사이트는 즉시 배포의 근거로 쓰기보다 다음 실험을 위한 새로운 가설로 활용하는 것이 정석입니다.
- MDE(최소 감지 효과)의 현실성 점검: 우리가 너무 미세한 차이를 잡아내려 한 것은 아닌지 확인해야 합니다. 전환율 0.01%p 수준의 상승을 잡아내려 했다면 비현실적으로 많은 표본이 필요합니다. 비즈니스 관점에서 무시해도 좋을 만큼 작은 차이라면 과감히 실험을 종료하고 더 큰 임팩트를 줄 수 있는 다른 가설에 집중하십시오.
- 가설의 근본적 재설계(Iteration) 디자인이나 문구를 바꿨음에도 지표 변화가 없다면 그 요소가 사용자의 의사결정에 영향을 주지 않는 부분일 가능성이 큽니다. 버튼 색상이나 자잘한 문구 수정을 넘어 가격 정책이나 가치 제안(Value Prop) 같은 더 거시적이고 본질적인 레버를 건드리는 가설로 전환해야 합니다.
p-value > 0.05는 가설이 틀렸거나 효과가 미미하다는 사실을 데이터로 증명한 성공적인 검증입니다. 실패에 당황하여 유의미한 결과가 나올 때까지 데이터를 계속 쪼개거나 실험을 무한정 연장하는 P-hacking을 경계해야 합니다. 또한 차이가 없는데도 B안이 조금 높으니까라며 무리하게 배포하는 결정은 서비스의 복잡도만 높이는 결과를 초래합니다. 결국 A/B 테스트 실무의 핵심은 p-value와 표본, 비즈니스 임팩트를 종합적으로 놓고 이 결과를 바탕으로 어떤 결정을 내릴 것인가를 도출하는 것입니다.
2.3. AB TEST 실험 보고서 템플릿: 실패가 아닌 성장의 밑거름
실험 결과가 차이 없음으로 나왔을 때, 단순히 결과 수치만 나열하기보다 우리가 무엇을 배웠고, 다음에 무엇을 할 것인가를 보여주는 것이 핵심입니다.
[템플릿] A/B 테스트 결과 분석 보고서
1. 실험 개요
실험명: 장바구니 버튼 문구 변경 테스트 (구매하기 vs 장바구니 담기)
실험 기간: 202X.XX.XX ~ 202X.XX.XX (14일간)
목표 지표: 최종 결제 완료율 (Conversion Rate)
2. 통계적 검증 결과 (The Truth)
결과: 통계적 유의성 미확보 (Inconclusive)
P-value: 0.24 (유의 수준 0.05 대비 높음)
지표 변화: 대안(B)이 원본(A) 대비 약 0.5% 높았으나, 이는 오차 범위 내의 차이로 우연에 의한 결과일 가능성이 큼.
3. 가설 복기 및 사후 분석 (Why?)
데이터 해석: 두 안의 차이가 미미했던 이유는 사용자들이 버튼 문구보다는 '상품의 가격'이나 '배송비'에 더 민감하게 반응했기 때문으로 추정됨.
세그먼트 분석: 전체 유저는 차이가 없었으나, '첫 방문자' 그룹에서는 B안이 소폭 우세한 경향을 보임 (단, 이 또한 추가 검증 필요).
4. 결론 및 향후 계획 (Next Action)
의사결정: 서비스 복잡도를 낮추기 위해 기존 원본(A)을 유지함. (불필요한 리소스 투입 방지)
차기 실험 가설: 문구 변경보다는 '무료 배송 혜택 강조'가 전환율에 더 큰 영향을 줄 것으로 판단됨. 다음 실험은 배송비 정보 노출 UI 변경으로 진행 예정.
3. 스포티파이 AB TEST 사례: 다중 지표 환경에서 명확한 의사결정 만들기

스포티파이는 매년 수만 건의 실험을 진행하면서도 의사결정의 혼선을 최소화하기 위해 리스크 인식 기반 의사결정 룰(Risk-aware Decision Rule)을 구축했습니다. 단순히 "주요 지표가 올랐으니 배포하자"가 아니라, 여러 지표를 종합적으로 판단하는 표준화된 기준을 만든 것입니다.
3.1. 스포티파이의 4가지 지표 체계와 배포 조건
스포티파이는 모든 실험에서 네 가지 유형의 지표를 추적합니다.
| 지표 유형 | 검정 방식 | 의미 |
|---|---|---|
| Success Metrics (성공 지표) | Superiority Test (우월성 검정) | 개선하려는 핵심 지표 (예: 청취 시간, 클릭률) |
| Guardrail Metrics (가드레일 지표) | Non-inferiority Test (비열등성 검정) | 악화되어서는 안 되는 보호 지표 (예: 구독 취소율, 일일 활성 사용자) |
| Deterioration Metrics (악화 감지 지표) | Inferiority Test (열등성 검정) | 실험으로 인한 회귀 버그 감지 (예: 로딩 시간, 오류율) |
| Quality Metrics (품질 지표) | 다양한 검정 | 실험 설계 자체의 무결성 검증 (예: 샘플 비율 불균형) |
그리고 다음 조건이 모두 충족될 때만 배포합니다.
최소 1개 이상의 성공 지표가 통계적으로 유의미하게 개선됨
모든 가드레일 지표가 허용 범위 내에서 비열등함 (악화되지 않음)
어떤 지표도 유의미하게 악화되지 않음
실험 품질 검증 통과 (샘플 비율 불균형 등 기술적 오류 없음)
3.2. 실제 사례: 성공과 보류, 두 가지 시나리오
사례 1: Discover Weekly - 성공적 배포
스포티파이의 개인화 추천 플레이리스트 실험은 리스크 관리 프레임워크를 어떻게 적용하는지 보여주는 대표 사례입니다.
- 가설: 개인화 추천 플레이리스트 제공 시 주간 청취 시간 증가
- 결과: 청취 시간 52% 증가 (p<0.001) + 모든 가드레일 지표 통과 → 전체 배포
- 핵심은 단순히 "청취 시간이 올랐다"가 아니라, 구독 취소율과 DAU 같은 장기 지표를 해치지 않으면서도 의미 있는 개선을 달성했다는 것을 입증한 데 있습니다.
사례 2: 홈 화면 재설계 - 배포 보류
- 모든 실험이 성공하는 것은 아닙니다.
- 가설: 카드 형식 레이아웃으로 클릭률 증가
- 결과: 클릭률 20% 상승 (p<0.01) ✓, 하지만 구독 취소율 3% 증가 ✗ → 배포 보류
클릭률은 대폭 개선됐지만 구독 취소율이 허용 범위를 초과했습니다. 단기 참여는 높였지만 일부 사용자에게는 사용성을 떨어뜨린 신호입니다. 스포티파이는 세그먼트별 원인 분석 후 레이아웃을 수정하여 재실험을 진행했고, 문제 해결 후 배포했습니다.
3.3. 실무 적용: 스포티파이 방식을 내 조직에 도입하는 법
스포티파이의 프레임워크는 규모가 작은 조직에서도 즉시 적용할 수 있습니다. 핵심은 실험 시작 전에 배포 조건을 명확히 정의하는 것입니다.
Step 1: 지표 정의 템플릿 작성
[실험명]: 결제 페이지 원클릭 결제 기능 추가
[성공 지표]
- 주 지표: 결제 완료율
- MDE: 기존 대비 최소 10% 상대 증가 (15% → 16.5%)
[가드레일 지표]
1. 평균 주문 금액(AOV): 기존 대비 5% 이상 하락하지 않을 것
2. 결제 오류율: 0.5%p 이상 증가하지 않을 것
3. 고객 만족도(CSAT): 유의미하게 하락하지 않을 것
[배포 조건]
- 결제 완료율이 통계적으로 유의미하게 개선되고 (p<0.05)
- 모든 가드레일 지표가 비열등 검증 통과 시 배포
[필요 표본]
- 각 그룹당 2,500명 (총 5,000명)
- 예상 실험 기간: 2주
Step 2: 의사결정 매트릭스 사전 합의
| 상황 | 의사결정 |
|---|---|
| 성공 지표 개선 + 모든 가드레일 통과 | 즉시 배포 |
| 성공 지표 개선 + 가드레일 1개 위반 | 배포 보류, 원인 분석 후 재실험 |
| 성공 지표 변화 없음 + 가드레일 통과 | 기존 안 유지, 학습 문서화 |
Step 3: 실험 후 회고
스포티파이는 실험의 성공을 "승리했는가"가 아니라 "충분한 정보를 얻어 명확한 결정을 내렸는가"로 측정합니다. 실험 종료 후 네 가지 질문에 답하세요.
- 명확한 배포/보류/롤백 결정을 내렸는가?
- 왜 이런 결과가 나왔는지 이해했는가?
- 이 학습을 다른 실험에 적용할 수 있는가?
- 다음에 어떤 가설을 세울 것인가?
4. 내일 바로 실무에 적용할 수 있는 체크리스트
실험은 '해봤다'는 기록이 아니라 '다음에 무엇을 할지 알게 된' 학습이어야 합니다. 실험하는 조직이 빠르게 성장하는 법: AB TEST(1)에서 만든 가설을 실제 성과로 연결하려면, 이번 글에서 다룬 검증 시스템이 필요합니다.
오늘 당장 시작할 수 있는 세 가지 실무 액션입니다:
1. 성공 지표 옆에 가드레일 지표 2개 추가하기
- 실험할 때 "이것만큼은 절대 나빠지면 안 된다"는 보호 지표를 함께 정하세요
- 예: 클릭률 올리기(성공 지표) → 이탈률, 평균 주문 금액(가드레일 지표) 동시 추적
2. 실험 전에 "최소 이 정도는 올라야 의미 있다" 기준 정하기
- "전환율이 최소 1%p는 올라야 리소스 대비 가치가 있다"처럼 팀과 합의하세요
- 이 기준으로 필요한 사용자 수와 실험 기간을 미리 계산하세요
3. 스포티파이식 실험 템플릿 사용하기
[실험 개요]
- 개선 영역: [고객 여정의 어느 단계]
- 현재 상황: [지금 지표 수치]
- 변경 사항: [구체적으로 무엇을 바꿀 것인가]
[가설]
- 예상 결과: [어떤 지표가, 얼마나 변할 것인가]
- 근거: [왜 그렇게 생각하는가 - 데이터나 심리학 원칙]
[실험 설계]
- 성공 지표: [올리려는 핵심 지표]
- MDE: [최소 이 정도는 올라야 성공]
- 가드레일 지표: [절대 나빠지면 안 되는 지표 2~3개]
- 필요 표본: [각 그룹당 몇 명]
- 실험 기간: [몇 주]
[배포 조건]
- 성공 지표가 통계적으로 개선되고
- 모든 가드레일 지표가 안전 범위 안에 있을 때 배포
이 세 가지만 실천해도, 실험이 끝났을 때 "이거 배포해도 될까요?"라며 회의실에서 논쟁하는 시간을 줄일 수 있습니다. 실험 시작 전에 이미 배포 조건을 정해뒀기 때문입니다.
결론: 검증 시스템이 성장 속도를 결정한다
출처: Netflix: Lessons in Experimentation - Product Growth Deep Dive
Netflix가 2007년 스트리밍 서비스를 시작했을 때, 그들은 "사용자가 무엇을 원하는지"에 대해 거의 아무것도 몰랐습니다. DVD 대여와 스트리밍은 완전히 다른 경험이었기 때문입니다. 그들이 선택한 방법은 간단했습니다. 모든 변경 사항을 가설로 만들고, 실제 사용자 데이터로 검증하는 것이었습니다. 15년이 지난 지금, Netflix는 매주 수백 개의 실험을 동시에 돌리며 2억 3천만 구독자가 매일 사용하는 경험을 최적화하고 있습니다.
Airbnb 역시 비슷한 여정을 걸었습니다. 2014년 그들의 실험 시스템은 주당 100개 미만의 테스트를 처리했습니다. 당시 조직은 어떤 아이디어를 먼저 실행할지 끊임없이 논쟁했고, 의사결정은 느렸습니다. 그러나 실험 인프라를 체계화하고 우선순위 프레임워크를 도입하면서 상황이 달라졌습니다. 2021년 기준 Airbnb는 주당 700개 이상의 실험을 진행하며, 동시에 매출은 5배 성장했습니다. 실험의 양이 늘어난 것이 아니라 검증 속도가 빨라진 것입니다.
두 기업이 증명한 것은 명확합니다. 성장 속도는 아이디어의 개수가 아니라 아이디어를 검증하는 시스템의 정교함에서 결정됩니다. 직관에 의존하는 조직은 10개 기능 중 3개가 성공하길 기대하며 기다립니다. 하지만 실험 기반 조직은 10개를 빠르게 테스트하고, 효과 없는 7개를 2주 만에 걸러내며, 성공한 3개를 즉시 확장합니다. 같은 시간, 같은 비용으로 전혀 다른 성장 곡선을 만들어냅니다.
혁신은 가장 좋은 아이디어에서 나온다. 하지만 성장은 가장 정확하게 검증된 아이디어에서 나온다. -Stefan Thomke
실험 문화는 CEO의 직관이나 임원의 경험을 부정하지 않습니다. 다만 그것을 가설로 전환하고, 데이터로 증명하거나 기각하는 과정을 거치게 만듭니다. 이 과정이 쌓이면서 조직은 "왜 고객이 이렇게 행동하는가"에 대한 이해를 축적하고, 실패는 낭비가 아니라 다음 가설을 더 정확하게 만드는 자산이 됩니다.
빠르게 성장하는 조직과 정체된 조직의 차이는 얼마나 빠르고 정확하게 가설을 검증하고 그 다음 액션을 수행하는지 입니다. 위그로스는 이 실험 문화를 조직에 안착시키고, 데이터 기반 의사결정으로 성장을 가속화하는 과정을 함께합니다.


