모델 성능에 대한 갈증이 옅어진 자리에서, 시간은 워크플로우와 생태계와 비용 최적화로 옮겨갔다. PM의 일이 capability 확보에서 오케스트레이션으로 바뀌는 중이다.
요즘 내 작업대에서 이상한 일이 벌어지고 있다. 모델은 한 달이 멀다 하고 더 좋아지는데, 정작 어떤 모델을 쓸지 고민하는 시간은 거의 0에 가깝다. 새 모델이 나왔다는 소식에 예전만큼 설레지도 않는다. 성능은 계속 좋아지는데, 나는 모델을 거의 신경 쓰지 않는다. 대신 시간은 전혀 다른 곳으로 가고 있다.
이 간극이 이 글의 출발점이다. 모델 성능에 대한 갈증이 옅어진 자리에 다른 일들이 시간을 가져간다. 제품을 다듬고, 워크플로우를 고치고, 무엇보다 그게 실제로 잘 작동하는지 eval하는 데 시간이 엄청나게 든다. 그리고 이리저리 도구를 만들다 보면 결국 손에 남는 일은 내가 쓰는 AI와 여러 AI 프로덕트 사이의 생태계를 정돈하는 것이다. 똑똑한 모델 하나를 고르는 일이 아니라, 모델들을 엮어 굴러가게 만드는 일이다.
이게 나 혼자의 착각은 아니다. 업계의 무게중심도 같은 곳으로 옮겨가고 있다. 모델을 더 똑똑하게 만드는 경쟁에서, 모델을 더 잘 굴리는 경쟁으로. 이 글은 그 이동을 현장에서 본 대로 정리한다. 결론을 먼저 말하면 이렇다. 모델이 흔해진 지금 중요한 건 모델이 아니라 그것을 둘러싼 세 가지다. 잘 깎인 워크플로우, 정돈된 생태계, 그리고 비용 최적화. 이 셋을 얼마나 잘 깎느냐가 지금 일의 핵심이고, 그게 PM의 직무를 다시 정의한다.
갈증이 모델에서 옮겨간 곳
지금 벌어지는 일은 한 문장으로 줄어든다. 경쟁의 전장이 모델에서 모델 바깥으로 나갔다는 것. 출시 주기가 짧아져 모델이 몇 주 만에 갈리면, 흔한 작업에서의 성능은 빠르게 평준화된다. 어제의 최고 모델이 다음 달이면 평범해진다. 그래서 프론티어 회사들은 더 똑똑한 모델 한 개가 아니라 그 모델을 둘러싼 운영 구조에서 싸우기 시작했다. 하네스와 오케스트레이션, 토큰 이코노믹스, 레이턴시가 모델 점수만큼 중요한 변수가 됐다.
한발 더 들어가면 요즘 엔지니어링 대화의 중심도 거기 가 있다. 서브에이전트 오케스트레이션, loop engineering, test-time compute, 데이터셋 엔지니어링, post-training. 공통점이 있다. 전부 모델 그 자체가 아니라 모델을 어떻게 굴리느냐에 관한 이야기다. 벤치마크 1, 2점을 더 따는 경쟁에서, 같은 모델을 더 싸고 빠르고 정확하게 작동시키는 경쟁으로 무게가 옮겨갔다.
이 변화가 중요한 이유는 갈증의 위치를 바꾸기 때문이다. 모델이 부족할 때는 더 좋은 모델이 모든 문제의 답이었다. 모델이 충분해지자 질문이 달라진다. 이 모델로 무엇을, 어떤 구조로, 얼마의 비용에 작동시킬 것인가. 희소한 자원이 지능에서 지능을 다루는 판단으로 옮겨간 것, 그것이 지금 일어나는 이동의 정체다. 모델은 흔해졌고, 흔해진 것은 부품이 된다.

현장의 시간은 이미 거기 가 있다
거시 트렌드를 멀리서 관찰한 게 아니다. 그 이동은 내 작업대에서 먼저 체감으로 왔다. 모델 성능에 목말라하기보다 제품을 다듬고 워크플로우를 손보는 데 시간을 쓴다. 어떤 모델을 쓸지는 거의 자동에 가깝고, 정작 손이 많이 가는 건 만든 것이 실제로 잘 작동하도록 만드는 일이다. 트렌드가 언어로 정리되기 전에, 현장이 먼저 그 방향으로 움직이고 있었다.
그중에서도 eval에 드는 시간이 압도적이다. 이건 비효율이 아니라 새 병목 그 자체다. 옛 질문은 "모델이 이걸 할 수 있나"였다. 지금 모델은 웬만하면 할 수 있다. 그래서 질문이 바뀐다. "그게 반복적으로, 믿을 만하게, 감당 가능한 비용으로 됐다고 어떻게 증명하나." eval은 AI 시대의 컴파일이고 QA다. 코드를 거의 공짜로 써 주는 모델 앞에서, 신뢰를 만드는 비용은 검증으로 옮겨간다.
도구를 만들다 보면 도착하는 곳도 정해져 있다. 결국 내가 쓰는 AI와 여러 AI 프로덕트 사이의 생태계를 정돈하는 일이다. 어느 모델을 어디에 붙이고, 무엇을 어떤 도구에 넘기고, 데이터가 그 사이를 어떻게 흐르는지를 가지런히 맞추는 작업이다. 현장에서 시간이 가는 곳은 모델이 아니라 모델들 사이의 연결과 검증이다. 거시가 말하는 시스템 경쟁을, 실무자는 매일의 손품으로 먼저 겪는다.

시스템에는 두 개의 기둥이 있다
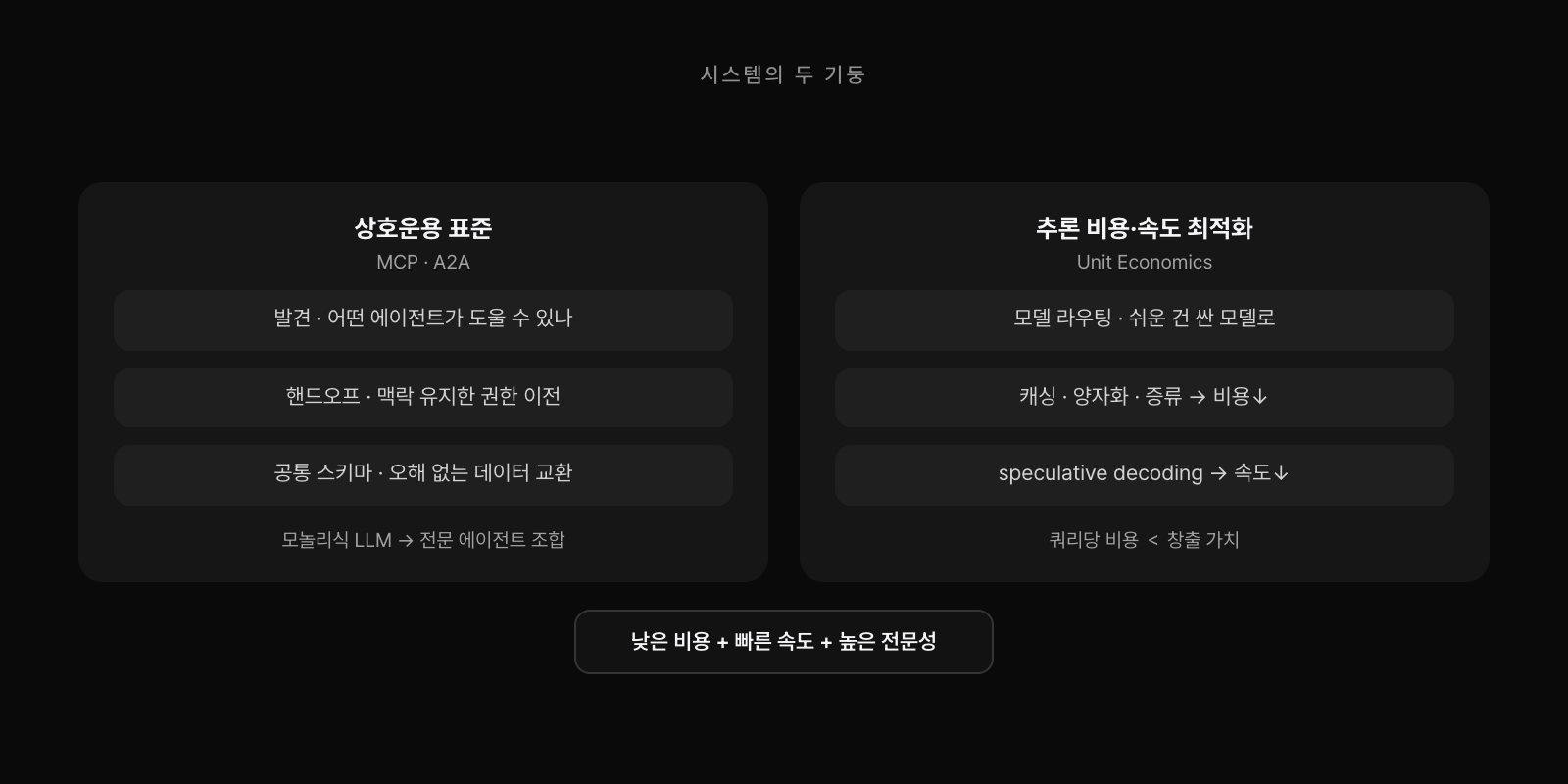
그 정돈에 이름을 붙이면 윤곽이 또렷해진다. 시스템 레이어는 크게 두 기둥으로 서 있다. 하나는 에이전트들을 서로 연결하는 상호운용 표준이고, 다른 하나는 그 위에서 비용을 깎는 추론 최적화다. 둘은 다른 문제를 풀지만 같은 목표를 향한다. 낮은 비용과 빠른 속도와 높은 전문성을 한꺼번에 잡는 것이다.
첫 기둥은 상호운용이다. 모든 기능을 하나의 거대한 모델 안에 욱여넣는 대신, 전문 분야가 다른 작은 에이전트들이 협력하게 만든다. 이때 서로 다른 팀이 만든 에이전트가 대화하려면 공통 규약이 필요하다. 어떤 에이전트가 내 일을 도울 수 있는지 찾는 발견, 맥락을 유지한 채 권한과 데이터를 넘기는 핸드오프, 같은 데이터 형식을 오해 없이 주고받는 공통 스키마가 그것이다. 실무에서 이 규약은 막연한 개념이 아니라 이름이 있다. 툴 연결의 사실상 표준이 된 MCP, 에이전트 간 협업을 맡는 A2A다. 둘 다 2025년을 지나며 리눅스 재단으로 넘어가, 주요 벤더 전부가 올라탄 공용 배관이 됐다.
둘째 기둥은 추론 비용과 속도의 최적화다. 비용을 직접 깎는 쪽엔 세 가지가 있다. 모든 질문에 가장 비싼 모델을 쓰지 않는 모델 라우팅, 반복되는 프롬프트를 다시 계산하지 않는 캐싱, 성능을 최대한 지키며 모델을 가볍게 만드는 양자화와 증류. 속도 쪽엔 작은 모델이 초안을 쓰고 큰 모델이 검수만 하는 speculative decoding이 있는데, 이건 총 연산을 줄이는 게 아니라 응답을 빠르게 하는 기법이라 비용이 아니라 레이턴시의 문제로 봐야 정확하다. 전문 에이전트를 표준으로 연결하고 그 안에서 비용과 속도를 최적화한 모델을 배치하는 것이 지금 AI 제품의 기본 골격이다. 이건 공학이자 PM의 설계 문제이고, 쿼리 한 번의 비용이 그것이 만드는 가치보다 작아야 제품이 산다.
닦을 것과 휘발될 것
그런데 이 정돈에는 함정이 있다. 끝이 없다는 것이다. 생태계를 가지런히 맞추는 일은 무한한 야크 셰이빙이 되기 쉽다. 본질에 닿으려고 곁가지를 치다 보면, 어느새 곁가지를 치는 일 자체가 일이 되어 있다. 솔직히 이 부분이 가장 피로하다. 도구를 정돈하려고 또 도구를 만들고, 그 도구를 다시 정돈하는 루프에 갇히는 감각이다.
피로의 진짜 원인은 땅이 계속 움직인다는 데 있다. 모델이 몇 주마다 바뀌면 어제 공들여 맞춘 최적화가 다음 달엔 과잉설계가 된다. 특정 모델의 약점을 메우려 짠 워크어라운드는 그 약점이 사라지는 순간 빚이 된다. 그래서 정돈의 기준은 지금 더 깔끔한가가 아니라 모델이 바뀌어도 살아남는 레이어인가여야 한다. 이 질문을 통과하지 못하는 정돈은 닦는 순간 이미 휘발되고 있다.
무엇이 살아남는지는 의외로 또렷하다. eval 하네스, 인터페이스 계약, 라우팅 정책은 모델이 바뀌어도 거의 그대로 쓴다. 반대로 특정 모델에 맞춘 프롬프트 미세 튜닝이나 단일 모델 의존 코드는 다음 세대에서 버려진다. 휘발될 것에 시간을 덜 쓰고 오래 갈 것에 더 쓰는 것이 정돈의 피로를 레버리지로 바꾸는 유일한 방법이다. 빠르게 전장을 바꾸는 경쟁 속에서, 무엇을 닦지 않을지 정하는 것이 무엇을 닦을지 정하는 것만큼 중요하다.

PM의 일은 확보에서 오케스트레이션으로
세 줄기가 한 점에서 만난다. 거시의 시스템 경쟁, 현장의 eval과 생태계 정돈, 그것을 떠받치는 상호운용과 비용 최적화. 전부 모델을 더 좋게 만드는 이야기가 아니라 모델을 더 잘 다루는 이야기다. 이 이동은 PM의 직무를 조용히 다시 쓴다. 옛 AI PM의 질문은 어떤 모델을 쓸까였다. 그건 capability를 확보하는 일이었다.
새 질문은 더 길다. 어떤 워크플로우로 생태계를 엮고, 어떤 모델을 어디에 배치해, 무엇을 어떻게 eval하며, 얼마의 토큰으로 굴릴 것인가. capability를 확보하는 일에서 그것을 오케스트레이션하는 일로 무게가 옮겨갔다. 모델은 매달 더 좋아지므로 더 이상 희소하지 않다. 희소한 것은 잘 깎인 워크플로우, 정돈된 생태계, 최적화된 비용 구조다. 그 셋을 깎아내는 판단이 AI-Native PM의 새 핵심 역량이다.
한 가지는 인정해야 한다. 오케스트레이션이 모델 능력을 대체하는 건 아니다. 잘 깎인 워크플로우도 모델이 못 하는 일을 만들어내진 못하고, 할 수 있는 일을 더 싸고 빠르고 미덥게 만들 뿐이다. 다음 세대 모델이 또 한 번 도약하면 오늘 공들인 정돈의 일부는 다시 불필요해질 것이고, 어쩌면 모델이 충분히 똑똑해져 오케스트레이션마저 스스로 하는 날이 올지도 모른다. 그래도 당분간은 분명해 보인다. 이제 중요한 건 모델이 아니라 그것을 둘러싼 워크플로우와 생태계와 비용이고, 그 셋을 잘 깎는 일이 지금 내가 하는 일의 새 이름이다.