이 글은 [조쉬의 뉴스레터]에서 발행되었습니다.
퀄리티 있는 프로덕트, 창업가, 비즈니스 이야기를 매주 구독해보세요.
구독 시 100개의 1인 창업 케이스 스터디가 발송됩니다.

안드레 카파시는 현대 AI를 직접 만든 사람 중 한 명이에요. OpenAI 공동창업자였고, 테슬라에서 오토파일럿을 굴러가게 만든 장본인이고, 작년에는 '바이브 코딩(vibe coding)'이라는 단어를 만들어낸 사람이에요. 그런 그가 최근 이렇게 말했어요.
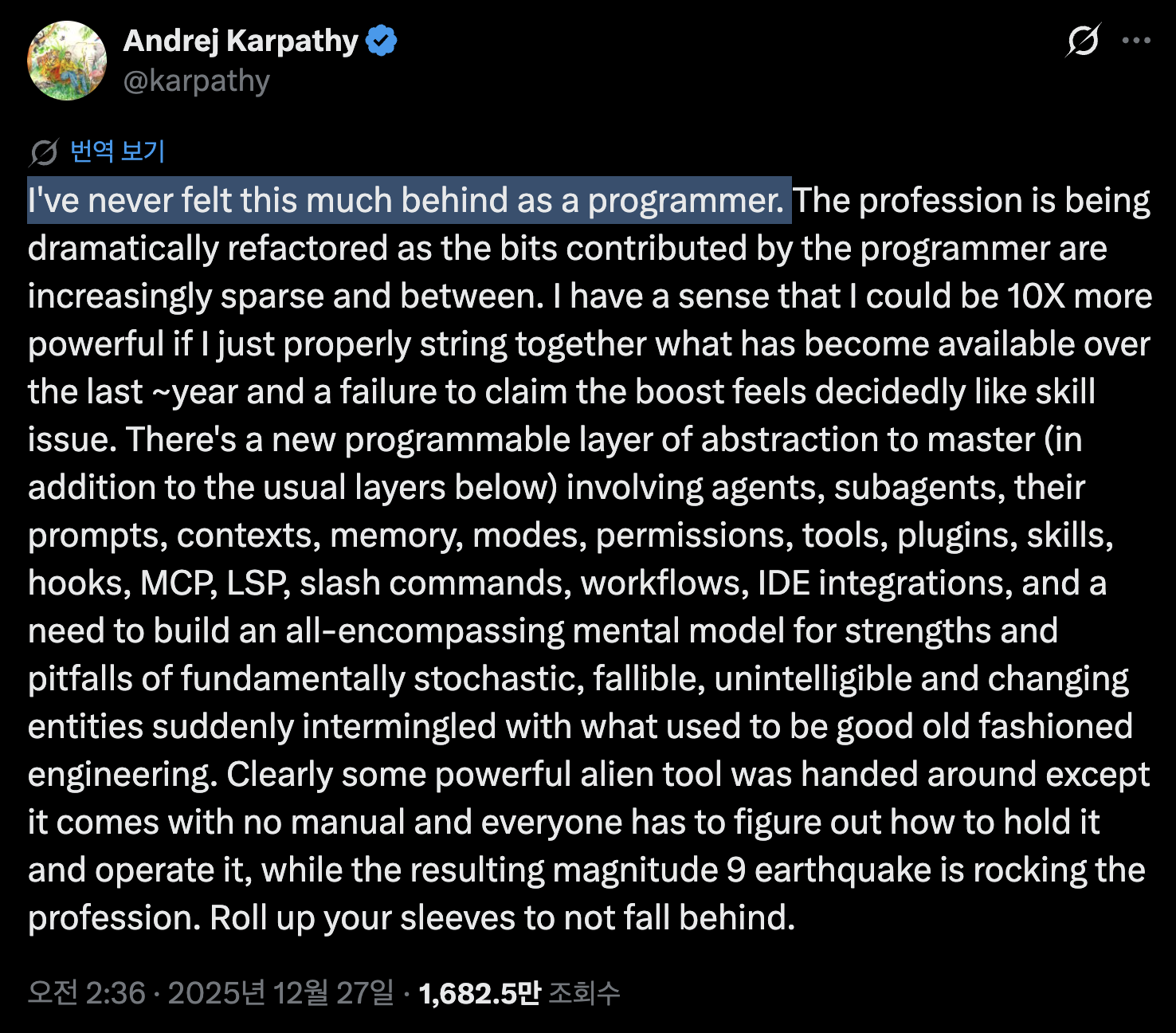
"프로그래머로서 이렇게 뒤처진 느낌은 처음이다." 작년에 챗GPT를 써보고 "이 정도구나" 하고 손을 뗀 사람이라면, 지금 다시 한번 들여다봐야 한다는 뜻이에요. 카파시 본인의 표현을 빌리면, "12월에 무언가 근본적으로 달라졌거든요."

12월에 일어난 일
Q. "프로그래머로서 이렇게 뒤처진 느낌은 처음"이라고 하셨어요. 그 말이 어떤 감정에서 나온 건가요?
설레면서도 불안한, 둘 다 섞인 감정이었어요. 저도 여러분처럼 작년 한 해 동안 클로드 코드(Claude Code) 같은 에이전트 도구들을 계속 써오고 있었거든요. 처음에는 코드 덩어리는 잘 짜주는데 가끔 실수해서 직접 고쳐줘야 하는 정도였어요. 도움은 되지만 완전히 맡기긴 어려운 수준이었죠.
이미지 출처 : @karpathy, X
Q. 그러다 12월에 뭔가 바뀌었다는 거죠?
네, 명확한 전환점이 왔어요. 저는 휴가 중이라 시간이 좀 더 있었고, 다른 사람들도 비슷했을 거예요. 최신 모델로 작업해보니 코드 덩어리가 그냥 깔끔하게 나오더라고요. 더 요청해도 또 깔끔하게 나오고. 마지막으로 제가 코드를 고친 게 언제였는지 기억이 안 날 정도였어요. 시스템을 점점 더 신뢰하게 됐고, 어느 순간 저는 바이브 코딩을 하고 있었어요.

이미지 출처 : @karpathy, X
Q. 그 변화를 사람들이 충분히 못 알아채고 있다고 보시는 거예요?
이건 굉장히 분명한 전환이었어요. X(트위터)에서도 이 점을 강조하려고 했는데, 많은 분들이 작년에 AI를 챗GPT 비슷한 무언가로 경험하고 거기서 멈춰 있거든요. 그런데 12월 기준으로 다시 봐야 해요. 정말 근본적으로 달라졌어요. 특히 에이전트가 일관된 워크플로를 따라가면서 실제로 일을 처리하는 부분에서요. 그 이후로 미친 듯이 파고들었어요. 사이드 프로젝트 폴더가 정말 말도 안 되게 꽉 차 있어요. 별별 잡다한 것들이 다 들어 있고, 계속 바이브 코딩을 하고 있어요.
소프트웨어 3.0이라는 새로운 컴퓨터
Q. LLM(대규모 언어 모델)을 새로운 컴퓨터라고 표현하셨어요. 단순히 더 좋은 소프트웨어가 아니라, 완전히 새로운 컴퓨팅 패러다임이라는 거잖아요. 이걸 진짜로 믿는 팀은 어떻게 일하는 게 달라져야 할까요?
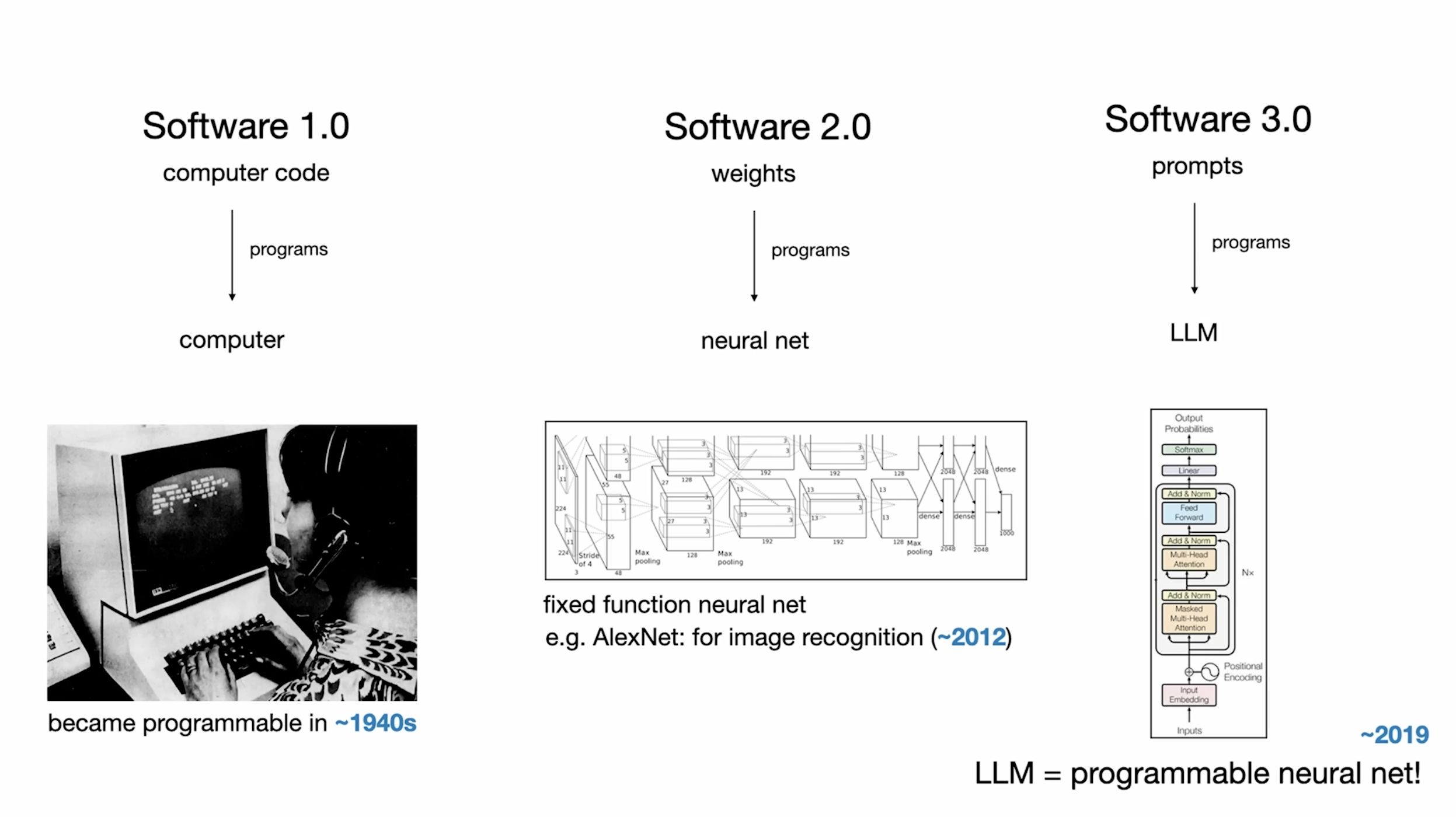
먼저 패러다임을 정리해볼게요. 소프트웨어 1.0은 코드를 직접 짜는 방식이에요. 소프트웨어 2.0은 데이터셋을 만들고 신경망을 학습시키는 방식, 그러니까 프로그래밍이 데이터셋을 정리하고 목적함수와 신경망 구조를 설계하는 일로 바뀐 거예요.
이미지 출처 : Youtube 'Y Combinator' 채널, - Andrej Karpathy: Software Is Changing (Again)
그리고 소프트웨어 3.0이 시작됐어요. GPT 같은 LLM을 충분히 다양한 작업으로 학습시키면, 인터넷 전체로 학습했기 때문에 데이터에 들어 있는 모든 작업을 동시에 처리하게 되거든요. 그러면 이게 어떤 의미에서는 프로그래밍 가능한 컴퓨터가 돼요. 소프트웨어 3.0은 프롬프트(AI에게 주는 명령어)로 프로그래밍하는 거예요. 컨텍스트 창(context window, AI가 한 번에 처리할 수 있는 정보의 범위)에 무엇을 넣느냐가 인터프리터(interpreter, 명령어를 해석해서 실행하는 프로그램) 역할을 하는 LLM을 조작하는 지렛대가 되고, 그게 디지털 정보 공간에서 연산을 수행하게 만들어요.
Q. 구체적인 예가 있을까요? 이걸 처음 깨달았을 때 어떤 사례가 가장 와닿으셨어요?
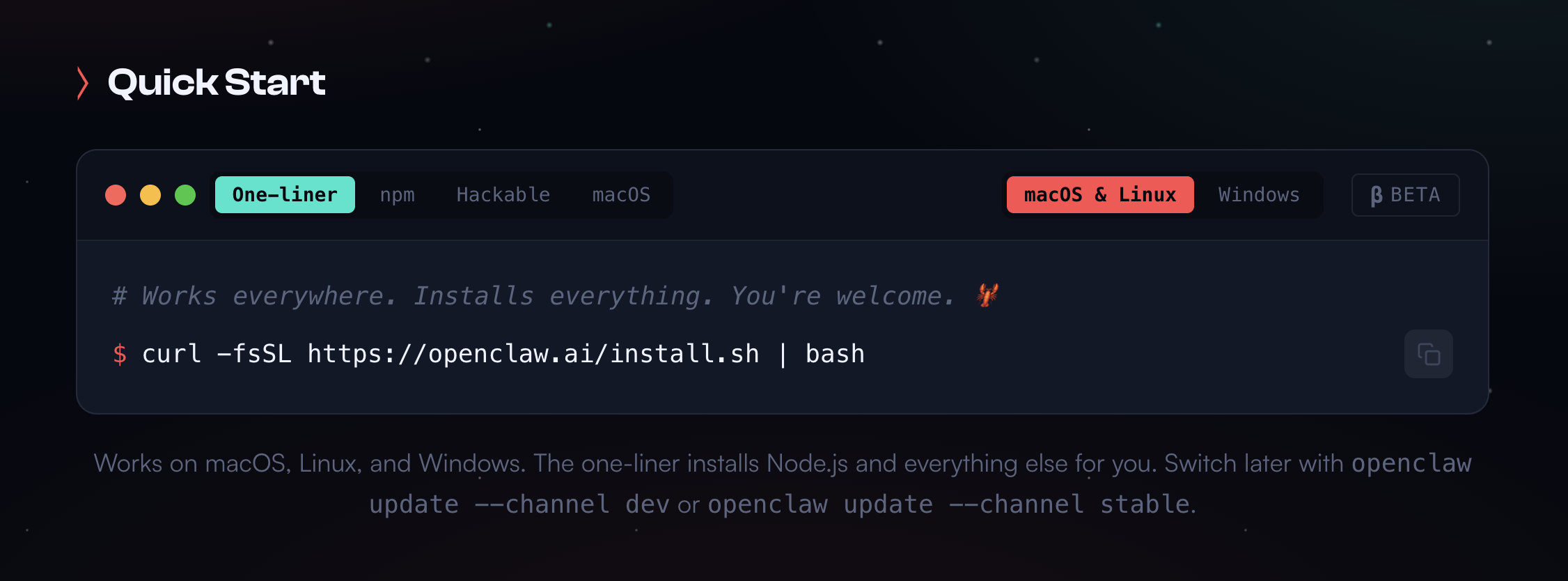
오픈클로(OpenClaw) 설치 방식이 좋은 예예요. 보통 이런 도구를 설치하려면 배시 스크립트(bash script, 컴퓨터에 명령어를 자동으로 실행해주는 텍스트 파일)를 받아서 실행해요. 그런데 다양한 운영체제와 환경을 다 지원하려면 이 스크립트가 어마어마하게 복잡해져요. 모든 경우의 수를 코드로 정확히 적어둬야 하니까요. 이게 소프트웨어 1.0 방식이에요.
이미지 출처 : openclaw
그런데 오픈클로의 실제 설치 방법은, 어떤 텍스트 덩어리를 복사해서 자기 에이전트한테 붙여넣는 거예요. 그러면 에이전트가 알아서 해줘요. 모든 세부사항을 일일이 적어둘 필요가 없거든요. 에이전트는 자기만의 지능이 있고, 사용자 환경을 살펴보고, 안 되면 디버깅도 하면서 결국 작동하게 만들어요. 그래서 소프트웨어 3.0 패러다임에서 프로그래밍은 이런 거예요. "에이전트한테 복사해서 붙여넣을 텍스트 덩어리는 무엇인가."
Q. 더 극단적인 예도 있다고 하셨어요.
네, 메뉴젠(MenuGen)이라는 프로젝트예요. 식당 메뉴판에 보통 사진이 없잖아요. 저는 메뉴를 봐도 30%, 어떨 때는 50% 정도는 무슨 음식인지 몰라요. 그래서 메뉴판 사진을 찍으면 각 음식이 어떻게 생겼는지 보여주는 앱을 만들고 싶었어요.

이미지 출처 : karpathy 블로그
그래서 바이브 코딩으로 만들었어요. 사진을 업로드하면 OCR(이미지에서 글자를 읽어내는 기술)로 메뉴 항목을 추출하고, 이미지 생성 모델로 각 항목의 사진을 만들어서 메뉴판처럼 다시 보여주는 거예요. 버셀(Vercel, 웹 서비스 배포 플랫폼)에 띄워서 잘 돌아갔어요.
그런데 며칠 뒤에 소프트웨어 3.0 버전을 봤어요. 충격이었어요. 메뉴 사진을 그냥 제미나이(Gemini)에 던져주고 "나노바나나(Nano Banana)로 메뉴 항목들을 이미지 위에 덧입혀줘"라고 시켜버린 거예요. 그러면 나노바나나가 제가 찍은 메뉴판 사진을 그대로 받아서, 픽셀 위에 각 음식의 그림을 직접 렌더링해서 돌려줘요.
Q. 그러니까 직접 만든 앱이 통째로 의미가 없어진 거잖아요.
맞아요. 제가 만든 메뉴젠은 통째로 군더더기였던 거예요. 그 앱은 옛날 패러다임에서 작동하고 있었고, 사실 존재할 필요가 없는 앱이었어요. 소프트웨어 3.0 패러다임은 훨씬 날 것에 가까워요. 신경망이 점점 더 많은 일을 직접 하고, 프롬프트나 컨텍스트는 그냥 이미지이고, 출력도 이미지이고, 중간에 앱이 필요 없어요. 사람들이 자꾸 기존에 있던 것들이 빨라지는 정도로만 AI를 보거든요. 하지만 그건 옛날 패러다임 안에서 생각하는 거예요. 새로운 가능성들이 생긴 거예요.
Q. 코드 바깥에서도 그런 새로운 가능성이 있을까요?
사실 이건 프로그래밍만의 문제가 아니에요. 일반적인 정보 처리가 자동화 가능해진 거예요. 기존의 코드는 정형화된 데이터(structured data)를 다뤘어요. 그런데 예를 들어 제가 하고 있는 LLM 지식 베이스(knowledge base, 정보를 정리해둔 저장소) 프로젝트를 보면, 조직이나 개인을 위한 위키(wiki, 누구나 편집할 수 있는 백과사전 형태의 문서)를 LLM이 자동으로 만들어주는 거예요.

이미지 출처 : gist.githubusercontent.com
이건 프로그램이 아니에요. 예전에는 존재할 수 없었던 거예요. 사실들로부터 지식 베이스를 만들어주는 코드 같은 건 없었거든요. 그런데 지금은 문서들을 던져주면 그걸 다른 방식으로 다시 컴파일하고, 재배열하고, 새롭고 흥미로운 재해석을 만들어내요. 그래서 저는 자꾸 이 지점으로 돌아가요. 기존에 있던 걸 빠르게 하는 것 말고, 아예 가능하지 않았던 새로운 기회들이요. 사실 이게 더 흥미로워요.
검증 가능성, AI가 잘하는 것과 못하는 것의 경계
Q. 검증 가능성(verifiability)이라는 개념을 자주 쓰시는데요. 출력이 검증 가능한 영역에서 AI가 가장 빨리 자동화된다는 얘기예요. 이게 정확히 무슨 뜻인가요?
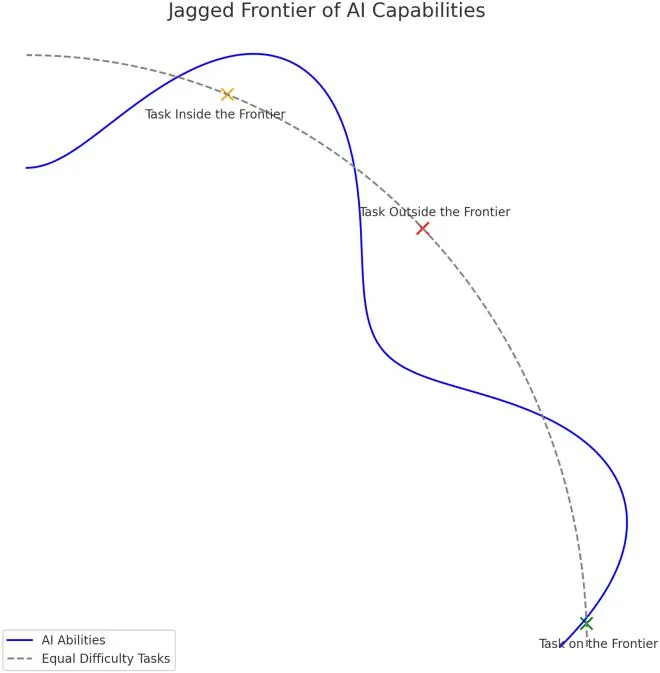
전통적인 컴퓨터는 코드로 명세할 수 있는 것을 자동화하기 쉬웠어요. 이번 세대 LLM은 검증할 수 있는 것을 자동화하기 쉬워요. 왜냐하면 프론티어 랩(frontier lab, 최첨단 AI를 만드는 연구소)들이 이 모델들을 학습시키는 방식이 거대한 강화학습(reinforcement learning, AI가 보상을 받으며 시행착오로 배우는 방식) 환경이거든요. 검증 보상(verification reward)을 주면서 학습시켜요.
이미지 출처: Professor KL Substack
그래서 모델들이 어떤 모양으로 나오느냐 하면, 들쭉날쭉한(jagged) 존재가 돼요. 수학이나 코드처럼 검증 가능한 영역에서는 능력이 정점을 찍는데, 그렇지 않은 영역에서는 정체되거나 거칠어요. 제가 검증 가능성에 대해 글을 쓴 이유도, 왜 이 모델들이 이렇게 들쭉날쭉한지 이해하고 싶어서였어요.
Q. 그게 단순히 학습 방법 때문만은 아니라는 거죠?
그것도 있고, 또 하나는 랩들이 무엇에 집중하느냐, 어떤 데이터를 분포에 넣느냐도 중요해요. 왜냐하면 어떤 영역은 경제적으로 훨씬 가치가 있어서 더 많은 환경이 만들어지거든요. 랩들이 그쪽에서 일하고 싶어하니까요. 코드가 좋은 예예요. 검증 가능한 환경 중에서, 그냥 충분히 유용하지 않아서 데이터에 들어가지 않은 영역들도 분명히 있을 거예요.
이미지 출처 : Dell'Acqua, Mollick et al., "Navigating the Jagged Technological Frontier" (HBS, 2023)
Q. 들쭉날쭉함을 보여주는 구체적인 예가 있을까요?
저한테 가장 큰 미스터리는요. 한동안 즐겨 들던 예가 "딸기(strawberry)에 r이 몇 개 있어?"였는데 모델들이 유명하게 틀렸거든요. 들쭉날쭉함의 한 예였죠. 지금은 이게 패치됐는데, 새로운 예가 있어요. "세차장이 50미터 거리에 있는데 차를 세차하러 가야 해. 운전해서 갈까, 걸어갈까?" 이렇게 물으면, 최신 모델들은 가까우니까 걸어가라고 대답해요.
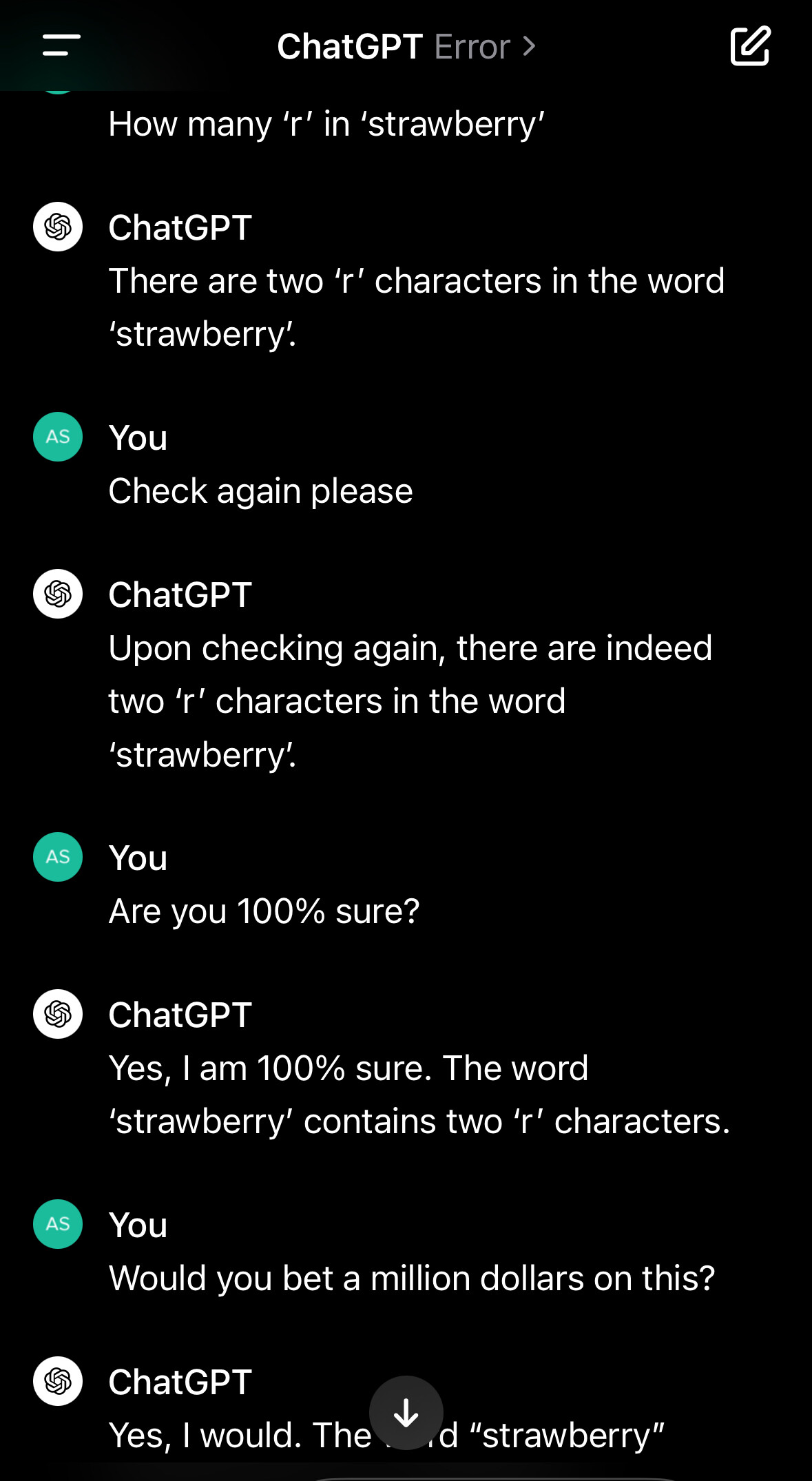
이미지 출처 : OpenAI Developer Community, @ashwinbalaji699
이게 어떻게 가능한 건지 모르겠어요. 최신 오푸스 4.7(Opus 4.7)은 동시에 10만 줄짜리 코드베이스를 리팩토링하거나 제로데이 취약점(zero-day vulnerability, 아직 알려지지 않은 보안 결함)을 찾아낼 수 있는데, 동시에 저한테 차 세차하러 걸어가라고 한다는 거잖아요. 말이 안 되죠.
이런 들쭉날쭉함이 뜻하는 건 두 가지예요. 첫째, 뭔가 살짝 어긋나 있다는 신호예요. 둘째, 사용자가 어느 정도 루프에 들어가 있어야 하고, 이걸 도구로 다뤄야 하고, 모델이 뭘 하고 있는지 계속 감을 잡고 있어야 한다는 뜻이에요.
바이브 코딩과 에이전트 엔지니어링
Q. 작년에 '바이브 코딩'이라는 단어를 만드셨잖아요. 그런데 지금은 분위기가 좀 더 진지한 '에이전트 엔지니어링'으로 흐르고 있는 것 같아요. 둘의 차이가 뭔가요?
바이브 코딩은 누구나 소프트웨어로 할 수 있는 일의 바닥을 끌어올리는 거예요. 바닥이 올라가서 누구든 무엇이든 바이브 코딩으로 만들 수 있어요. 멋지죠. 놀라운 일이에요.
이미지 출처 : @karpathy, X
에이전트 엔지니어링은 다른 거예요. 기존 전문 소프트웨어가 갖고 있던 품질 기준선을 유지하는 일이에요. 바이브 코딩 때문에 보안 취약점을 들여놓으면 안 되고, 자기 소프트웨어에 대한 책임은 예전과 똑같이 져야 해요. 그러면서도 더 빠르게 갈 수 있느냐, 어떻게 그걸 제대로 할 수 있느냐. 스포일러는, 할 수 있어요.
Q. '엔지니어링'이라는 단어를 붙인 이유가 있을까요?
에이전트들은 들쭉날쭉하고, 살짝 변덕스럽고, 약간은 확률적인(stochastic, 매번 결과가 조금씩 달라지는) 존재예요. 동시에 엄청나게 강력하기도 해요. 이런 존재들을 어떻게 조율해서 품질 기준은 그대로 두면서 더 빠르게 갈 수 있느냐. 그걸 잘하고 정확하게 하는 게 에이전트 엔지니어링의 영역이에요.

이미지 출처 : @karpathy, X
그래서 둘은 다른 거예요. 하나는 바닥을 올리는 일이고, 다른 하나는 위로 끝까지 밀어붙이는 일이에요. 제가 보기에 에이전트 엔지니어링 능력의 천장은 정말 높아요. 예전에 10배 엔지니어 얘기 많이 했잖아요. 이제 10배는 더 이상 충분한 표현이 아니에요. 이걸 정말 잘하는 사람들은 10배보다 훨씬 더 정점을 찍어요.
Q. 작년에 샘 알트먼이 말하길, 30대는 챗GPT를 구글 검색 대체로 쓰고, 10대는 인터넷 진입로로 쓴다고 했어요. 코딩에서는 어떻게 나뉠까요? 두 사람이 클로드 코드나 코덱스(Codex)를 쓰는데, 한 명은 평범하고 한 명은 완전히 AI 네이티브라면 차이가 어디서 보일까요?
도구를 최대한 활용하려고 노력하는 사람이에요. 모든 기능을 다 써보고, 자기 셋업(setup, 작업 환경)에 투자하는 사람이요. 예전에도 엔지니어들은 자기가 쓰는 도구, 빔(Vim)이든 VS Code든, 아니면 지금의 클로드 코드나 코덱스든, 거기서 최대한을 뽑아내려고 했잖아요. 셋업에 투자하고, 사용 가능한 모든 도구를 활용하는 거예요.

Q. 에이전트가 더 많은 일을 대신하면, 사람의 어떤 능력이 더 가치 있어질까요?
지금 에이전트들은 인턴 같은 존재예요. 놀라운 인턴이지만요. 그래서 사람은 여전히 미적 감각, 판단, 취향, 그리고 어느 정도의 감독을 책임져야 해요.
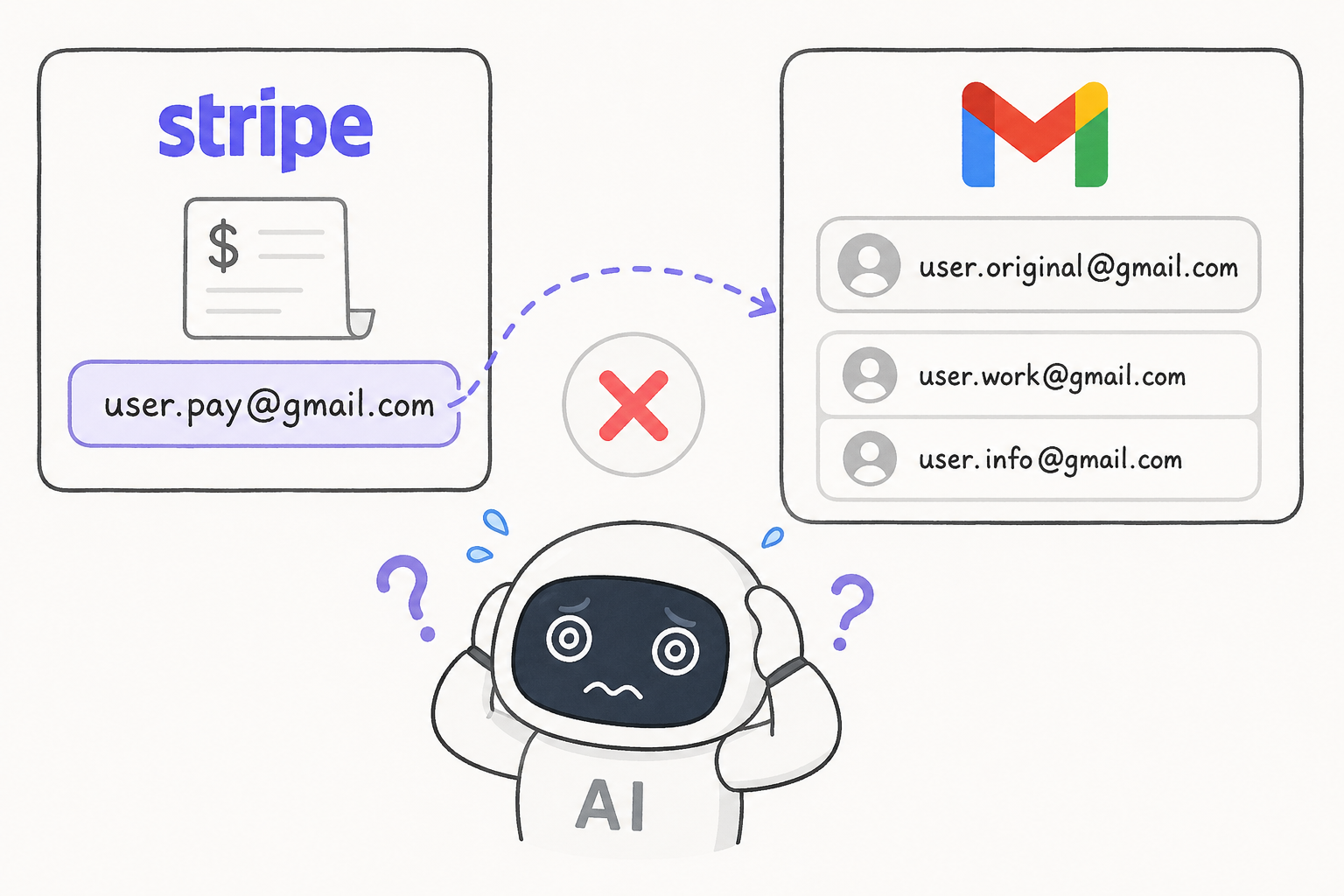
제가 좋아하는 예가 하나 있어요. 메뉴젠을 만들 때, 사용자는 구글 계정으로 가입하지만 결제는 스트라이프(Stripe)로 해요. 둘 다 이메일 주소를 갖고 있죠. 그런데 제 에이전트가 결제를 처리할 때, 스트라이프에서 받은 이메일 주소를 구글 이메일 주소와 맞춰서 사용자를 식별하려고 하는 거예요. 영구적인 사용자 ID가 없으니까, 이메일 주소로 매칭하려는 거였죠.
이미지 출처 : 나노바나나 제작
그런데 사람들은 스트라이프와 구글에 다른 이메일을 쓸 수 있잖아요. 그러면 결제 금액이 사용자랑 연결이 안 돼요. 이런 게 에이전트가 여전히 실수하는 영역이에요. 왜 이메일 주소로 자금을 매칭하려고 해? 그건 임의로 다를 수 있는데? 너무 이상한 결정이거든요.
Q. 그러면 사람은 뭘 책임져야 하는 거예요?
명세(spec)와 계획을 책임져야 해요. 저는 사실 플랜 모드(plan mode, AI가 작업 계획을 먼저 짜는 기능) 자체를 그렇게 좋아하진 않는데요. 좀 더 일반적인 무언가가 있어요. 에이전트와 함께 굉장히 자세한 명세를 설계하고, 그걸 문서로 만들고, 그 문서를 에이전트가 직접 작성하게 하고, 사용자는 감독과 최상위 카테고리를 책임지는 거예요. 세부사항은 에이전트가 처리하고요. 사람은 취향(taste), 엔지니어링, 디자인, 그리고 판단을 책임져요. 사람이 디자인과 개발을 하고, 에이전트가 빈칸을 채우는 식이에요. 지금은 그래요.

이미지 출처 : Youtube 'The New Code', by Sean Grove, OpenAI
Q. 이 취향과 판단력이 시간이 지나면 덜 중요해질까요, 아니면 천장이 계속 올라갈까요?
AI의 미적 감각도 결국 좋아질 거라고 기대해요. 지금 안 좋아지는 이유는 강화학습에 들어가 있지 않거든요. 미적 감각에 대한 비용이나 보상이 따로 없거나, 있어도 충분치 않은 거예요.
실제로 코드를 들여다보면 가끔 심장이 좀 철렁해요. 항상 굉장한 코드가 나오는 건 아니거든요. 부풀어 있고, 복사 붙여넣기가 많고, 어색한 추상화가 있고, 깨지기 쉬워요. 동작하긴 하는데 그냥 좀 끔찍해요. 그래서 사람은 여전히 이걸 책임져야 해요. 다만 이걸 막는 근본적인 이유가 있는 건 아니에요. 그냥 랩들이 아직 거기까지 안 한 거예요.
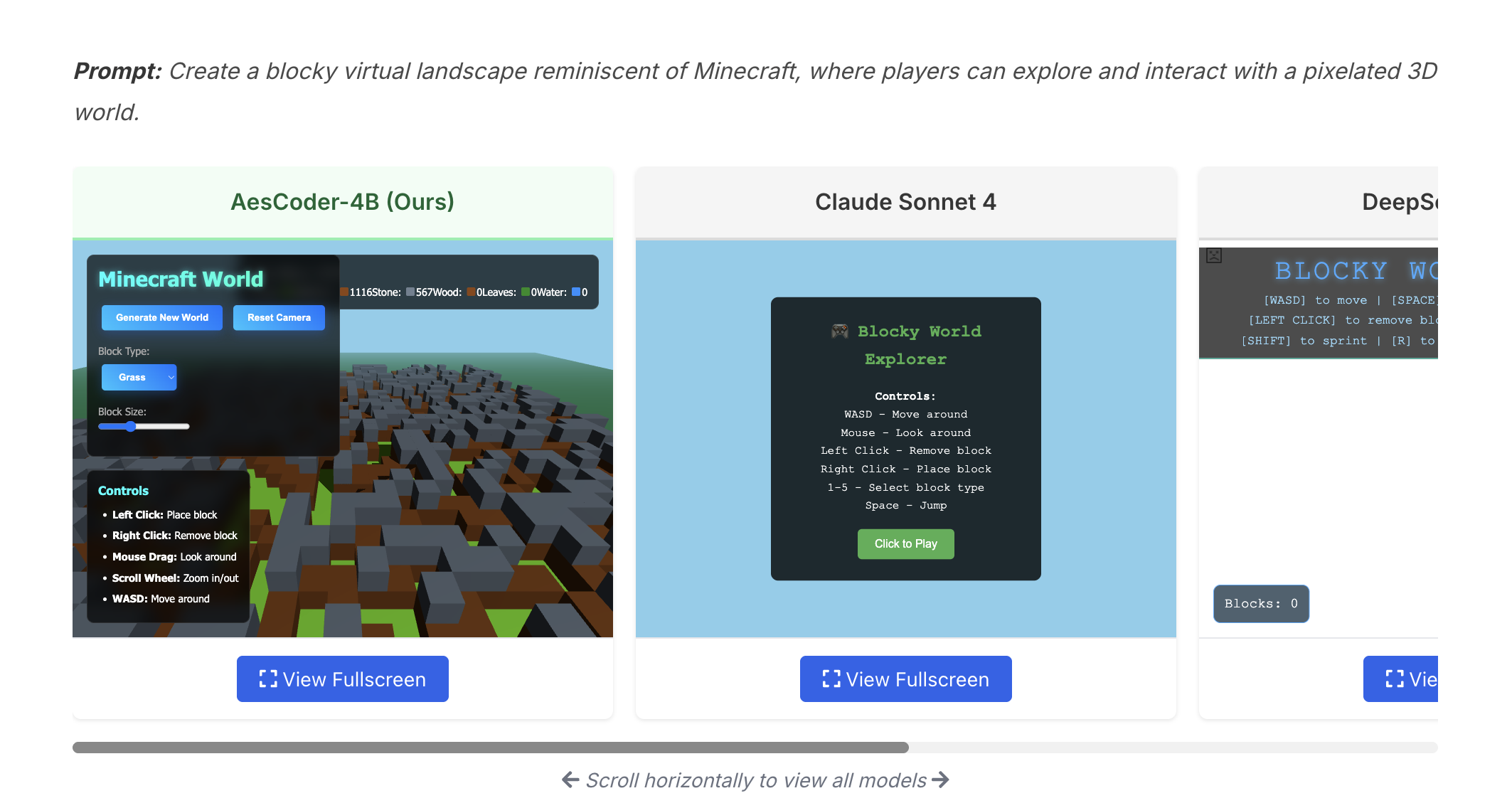
이미지 출처 : "Code Aesthetics with Agentic Reward Feedback", Microsoft Research
에이전트가 권한과 행동을 갖게 될 때
Q. 채팅만 하는 게 아니라, 실제 권한을 갖고, 로컬 컨텍스트를 갖고, 사용자 대신 행동하는 에이전트를 깊이 다루고 계시잖아요. 우리 모두가 그런 세상에서 살게 되면 어떻게 보일까요?
여기 계신 많은 분들이 에이전트 네이티브 환경이 어떤 모습일지 기대하고 계실 거예요. 모든 게 다시 쓰여야 해요. 지금 모든 게 사람을 위해 쓰여 있거든요.
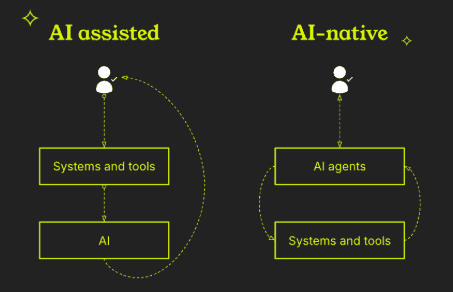
이미지 출처 : resolve.ai, 'The role of multi agent systems in making software engineers AI-native'
저는 지금도 다양한 프레임워크나 라이브러리를 쓸 때 대부분의 문서가 사람을 위해 쓰여 있어서 답답해요. 왜 사람들이 아직도 저한테 뭘 하라고 말하고 있죠? 저는 아무것도 하고 싶지 않거든요. (웃음) 제 에이전트한테 복사해서 붙여넣을 텍스트 덩어리는 어디 있어요? "이 URL로 가세요" 같은 말을 들을 때마다 진짜 답답해요.
Q. 그러면 인프라가 어떻게 바뀌어야 할까요?
워크로드(workload, 처리해야 할 작업)를 분해해서 본질적으로 세상에 대한 센서(sensor)와 액추에이터(actuator, 행동을 일으키는 장치)로 만들어야 해요. 어떻게 하면 에이전트 네이티브로 만들 수 있느냐. 에이전트한테 먼저 설명되도록요. 그리고 LLM이 읽기 쉬운 데이터 구조 주변에 자동화를 많이 두는 거예요.
이미지 출처 : arxiv.org/abs/2307.07924
메뉴젠을 만들 때 가장 골치 아팠던 건 사실 코드가 아니었어요. 버셀에 배포하는 거였죠. 여러 서비스를 다 연결하고, 설정에 들어가서 메뉴를 뒤지고, DNS를 손보고. 너무 짜증났어요. 이상적으로는 LLM한테 "메뉴젠 만들어줘" 한 번 던지면 제가 아무것도 건드리지 않아도 인터넷에 그대로 배포되는 거예요. 그게 우리 인프라가 점점 더 에이전트 네이티브가 되고 있는지를 보는 좋은 테스트예요. 더 멀리 가면, 사람과 조직을 위한 에이전트 대표가 있는 세상으로 가고 있다고 봐요. "내 에이전트가 네 에이전트랑 얘기해서 우리 미팅 일정 같은 거 정해줘." 이런 식으로요.
Q. AI 시대에 지능이 정말 싸졌을 때, 그래도 깊이 배울 가치가 남아 있는 게 뭘까요?
최근에 머리를 친 트윗이 하나 있었어요. 며칠에 한 번씩 자꾸 떠올라요. 대략 이런 내용이었어요. "사고는 외주를 줄 수 있지만, 이해는 외주를 줄 수 없다."
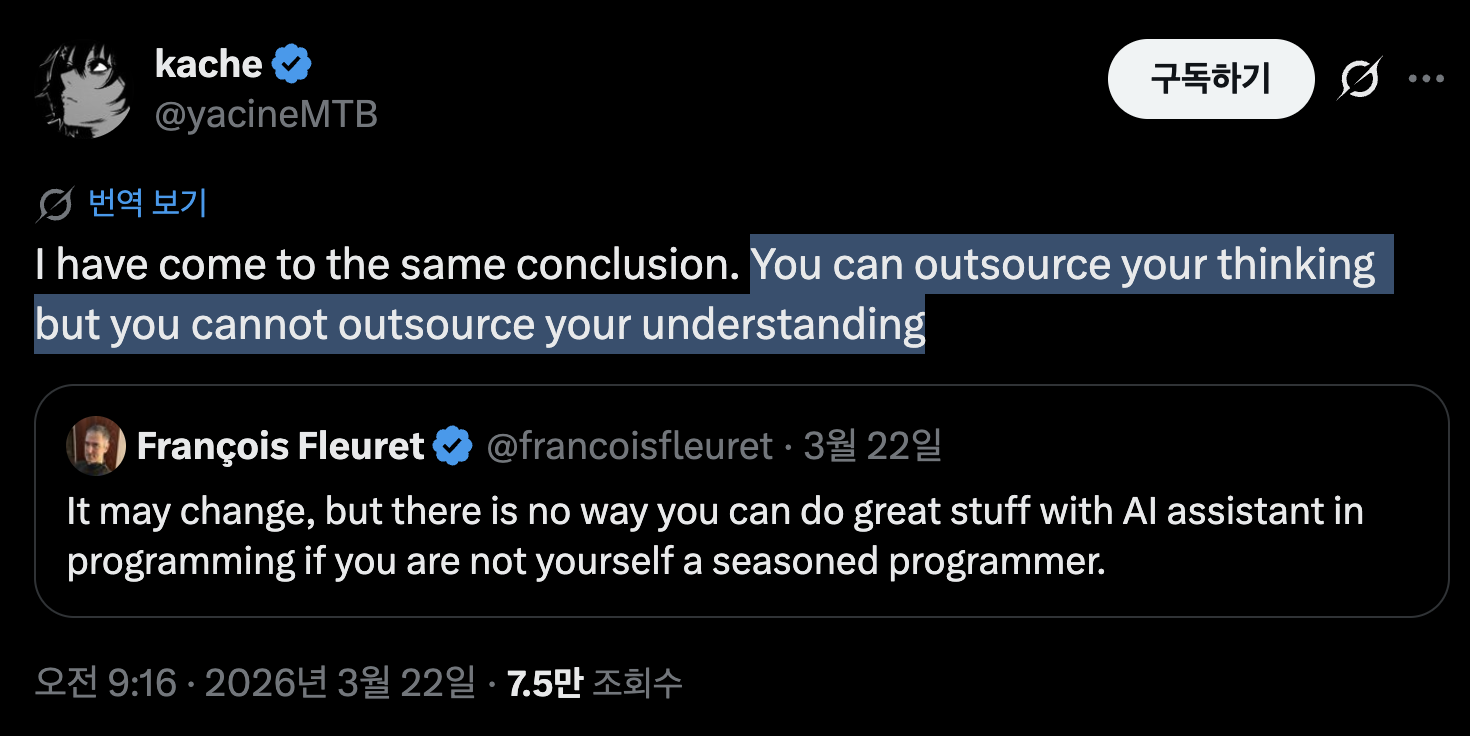
이미지 출처 : @yacineMTB, X
정말 잘 표현했다고 생각했어요. 저는 여전히 시스템의 일부예요. 정보가 어떻게든 제 뇌에 들어와야 해요. 그리고 저는 점점 병목이 되고 있어요. 우리가 뭘 만들려고 하는지, 왜 그게 할 만한 가치가 있는지, 어떻게 에이전트를 지휘해야 하는지 같은 것들이요. 결국 무언가가 사고와 처리를 지휘해야 하는데, 그건 여전히 이해라는 능력에 의해 근본적으로 제약돼요.

오늘 레터가 좋았다면, 조쉬의 뉴스레터를 주변에 알려주시거나, 구독을 해주세요. 소중한 노력이 들어간 글을 널리 알려주세요.
이 기사가 좋으셨다면, 보상을 해주세요.
가장 좋은 보상은 ‘조쉬의 뉴스레터 구독’입니다. :)
구독을 하시면 100개의 1인 창업가 데이터베이스를 발송해드립니다.

