Karpathy 위키에 의미 검색을 붙인 4일, 핵심은 요약 레이어였다.
Andrej Karpathy의 LLM 위키 개념을 업무 추적에 적용한 지난 글에서 5계층 DAG를 설계하고, 세션 훅으로 데이터가 레이어를 타고 흐르게 강제했다. 42일치 데이터가 8개 Concept 패턴으로 구조화되는 것까지 확인했다. 시스템은 돌기 시작했지만, 며칠 쓰고 나니 다른 구멍이 보였다.
위키링크는 정확한 이름을 알 때만 동작하는 레일이다. "예전에 Stop 훅 왜 포기했지?" 같은 흐릿한 기억은 잡히지 않는다. 기록한 단어가 "세션 종료 감지"인데 기억 속 단어는 "Stop 훅"이면 grep은 0건이다. 단어 하나가 어긋나면 검색이 즉사한다.
지난 글은 '어떻게 쓸 것인가'에 관한 하네스 이야기였다. 이번 글은 그 뒷면이다. 쓴 것이 실제로 검색되고 호출되기까지 또 다른 하네스가 필요했다. 이 글은 그 구멍을 메우려고 의미 검색 레이어(gbrain)를 붙이고, 조용히 죽은 인프라를 되살리고, 검색 정답률을 10문항 중 4문항에서 10문항까지 끌어올린 4일의 빌드로그다. 4일을 지나고 확인한 것은 기술적 최적화가 아니었다. raw가 있어도 요약이 없으면 찾을 수 없다는 Karpathy 원칙의 진짜 의미를 벤치마크로 증명한 것이 실제 페이오프였다.
위키링크만으로는 부족했다
Worklog 볼트는 옵시디언 단일 볼트이고, 위키링크로 Daily와 Projects, Tasks, Concepts를 연결한다. 정확한 이름을 알면 [[Projects/oh-my-hwclaude]]로 곧장 점프한다. 문제는 모를 때다. "예전에 gbrain에 docker 써야 한다고 했었지?"라는 질문에서 뇌가 주는 앵커는 "gbrain" 하나뿐이고 나머지는 흐릿하다. 기록한 단어와 기억하는 단어가 다르면 grep은 0건을 돌려준다.
표준 해결책은 의미 검색이다. 텍스트를 벡터로 임베딩하고, 쿼리도 같은 공간에 임베딩해 유사도로 매칭한다. Postgres + pgvector 조합이 가장 가볍고, 임베딩은 Google gemini-embedding-001을 쓰면 비용이 0이고 한국어 품질도 충분하다.
2026-04-11, Postgres 컨테이너에 pgvector extension을 얹었다. Docker를 쓴 건 당시 Nous Research의 오픈소스 자율 에이전트 Hermes Agent를 같이 셋업하던 흐름이 있었기 때문이고, gbrain도 그 흐름 위에 같이 탔다. 마크다운을 Postgres로 인덱싱하는 gbrain 오픈소스 툴에 임베딩 provider를 Google로 패치하고, Worklog 101페이지를 넣으니 145개 청크가 나왔다. .mcp.json에 gbrain MCP 서버를 등록하고 post-commit 훅으로 커밋마다 incremental sync가 돌게 걸었다. 이제 Claude Code 세션에서 mcp__gbrain__query("세션 종료 훅 왜 포기")를 호출하면 "Stop 훅을 신뢰할 수 없어 git push 트리거로 전환"이 담긴 Daily가 top-1로 잡혔다. 위키링크가 못 잡는 질문을 의미 공간에서 낚아 올리는 레이어가 생긴 것이다.

인프라를 깔아놓고 아무도 안 썼다
문제는 여기부터였다. 인프라는 멀쩡히 돌고 있었는데 쿼리가 거의 들어오지 않았다. Claude Code 세션에서 "지난번에 이 결정 왜 했지?" "예전에 해본 건데 왜 뺐지?" 같은 질문이 하루에 몇 번씩 나오는데도, 모델의 첫 반사는 여전히 grep이었다. 의미 검색 레이어는 설치했는데, 아무도 쓰지 않는 상태였다.
2026-04-12에 메모리 시스템 3계층(Auto Memory, Worklog, Gbrain)을 분석하다가 이 구멍이 명시화됐다. gbrain은 consumer 없는 인프라였다. 그 자리에서 은퇴 제안이 나왔지만 "언제 쓸지 모름"이라는 이유로 유지됐다. 이틀 뒤인 04-14, Docker daemon이 죽어 있었다. post-commit 훅은 살아 있었지만 컨테이너가 내려가서 sync가 silent fail 중이었다. 04-12의 "보류"가 04-14의 "조용히 죽어 있음"으로 실현된 순간이었다. dormant 인프라는 고장 나도 아무도 눈치채지 못한다. 이것이 dormant의 진짜 비용이다.
이러한 상태에서 해결은 두 방향으로 갔다. 하나는 Docker 탈출이다. 같이 탔던 Hermes가 작업 패턴에 맞지 않아 떨어져 나가면서 gbrain은 단독 소비자가 됐고, 단독이 되니 Docker Desktop이 먹는 RAM 1~2GB는 순수 오버헤드였다. Homebrew native postgresql@18과 pgvector 0.8.2로 마이그레이션했다. DB URL을 동일하게 유지해서 .mcp.json도 훅도 한 글자 바꾸지 않았고, 원본 마크다운이 볼트에 그대로 있으니 재인덱싱 비용은 0이었다. RAM은 100MB 미만으로 떨어졌다.
다른 하나는 호출이 안 일어나는 진짜 이유를 구조로 고치는 것이었다. ~/.claude/rules/worklog-search-priority.md라는 규칙 파일 하나로 Claude Code의 행동을 강제했다. 과거 시제와 업무 명사 조합 같은 트리거 패턴이 감지되면 첫 툴 호출 전에 gbrain을 무조건 먼저 호출하도록 박았고, 0건일 때만 ripgrep으로 폴백하도록 했다. 이 룰 하나로 Claude Code가 gbrain의 1순위 소비자가 됐다. 인프라를 깔기만 해서는 안 됐던 것이다. 설치와 호출 사이에는 구조적 연결이 필요했고, 그 연결이 없으면 인프라는 dormant로 내려앉는다.
Retrieval 4/10에서 10/10까지
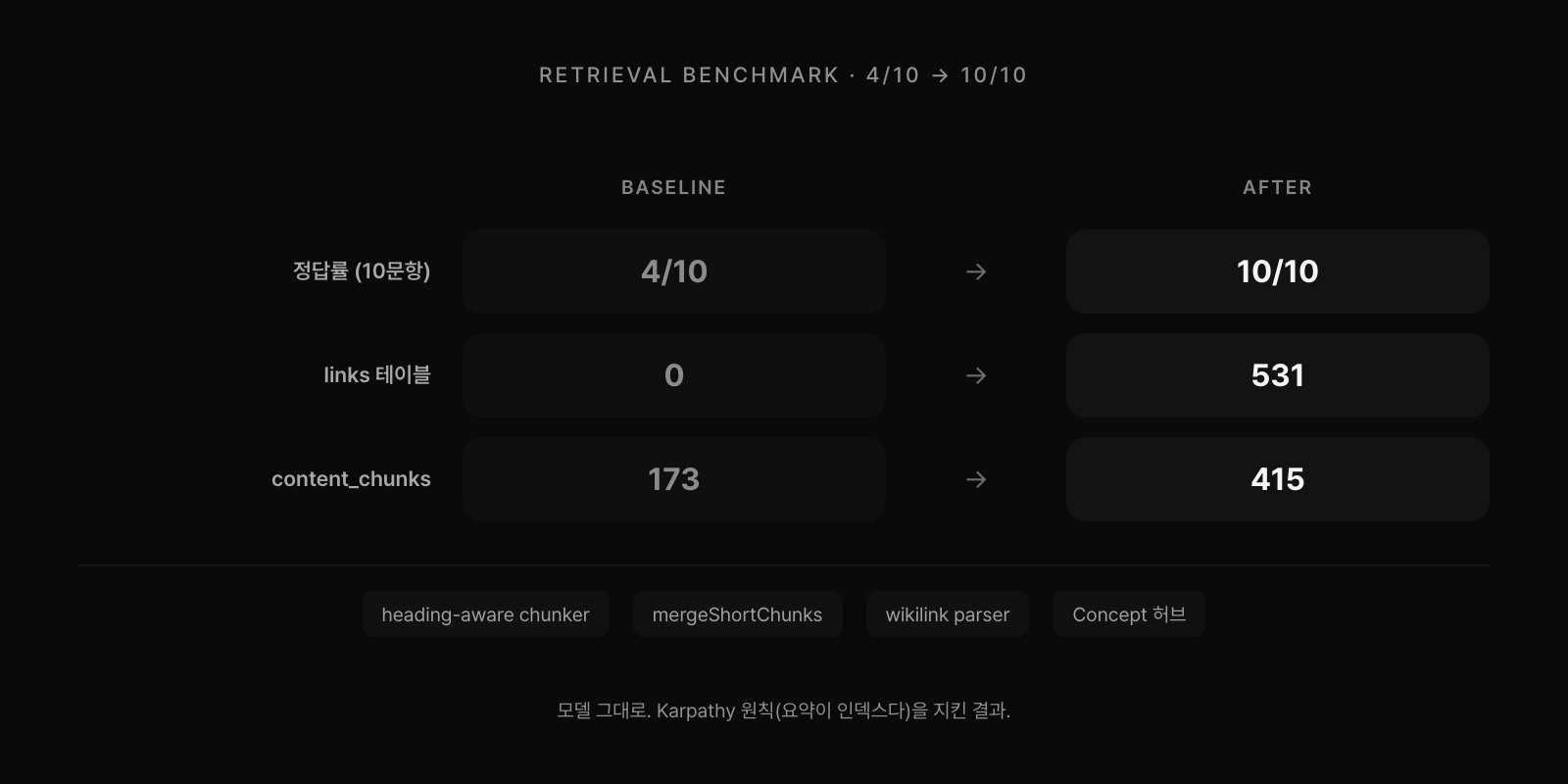
소비자가 생기니 다음 문제는 답의 품질이었다. 실제로 던질 만한 질문 10개를 벤치마크로 뽑았다. "메타 시스템 투자는 어느 시점에 누적됐지?" "Stop 훅 왜 포기했지?" "Karpathy 패턴은 어디서 차용됐지?" 각 질문에 정답 Daily를 지정하고, gbrain이 top-K 안에 정답을 포함시키는지 측정했다. baseline은 10개 중 4개, 정답률 40%였다. 위키링크 걸어놓고, MCP로 붙이고, 훅으로 sync 돌려도 절반도 못 맞췄다.
원인은 세 가지가 겹쳐 있었다. 첫째는 청크 경계가 임의적이라는 것이었다. gbrain 기본 설정이 고정 크기로 텍스트를 자르니 하나의 의사결정이 두 청크에 걸쳐 잘렸고, ##/###를 HARD boundary로 쓰는 heading-aware chunker를 넣어 한 블록이 한 청크에 담기도록 했다. 둘째는 짧은 청크가 top-1을 독점하는 현상이었다. 30자 미만의 제목·메타 줄이 임베딩 공간에서 일반 쿼리와 비슷하게 찍혀서 긴 청크를 제쳤고, mergeShortChunks 후처리로 기준 미만 청크를 이전 청크에 병합했다.
세 번째 원인이 가장 중요했다. 요약 레이어 자체가 부족했다. "메타 시스템 투자"를 물으면 gbrain은 raw Daily 7~8개를 찾아야 하는데, 각 Daily는 그날 작업한 일부 조각만 담고 있어서 추상 개념에 매칭될 강한 신호가 인덱스에 없었다. 해결은 Concept 노드 하나였다. Concepts/meta-system-investment.md라는 허브 노트를 만들고 Worklog 자동화·gbrain 지식 뇌·pre-push 체크포인트 같은 상위 인프라 투자를 횡단 주제로 묶어 관련 Daily에 백링크를 걸었다. 이 허브를 만들자 "메타 시스템 투자" 쿼리가 이 Concept을 top-1으로 잡았다.
이러한 과정에서 Karpathy 원칙의 진짜 의미가 다시 읽혔다. 지난 글에서는 5계층 DAG를 "데이터가 흐르는 레이어"로 설명했는데, 그것은 절반짜리 해석이었다. 진짜 역할은 검색 인덱스다. Concepts는 사람이 읽기 위해 쓰는 문서가 아니라, LLM이 raw 데이터를 찾을 때 쓰는 라우팅 테이블이다. raw는 있는데 요약이 없으면 검색에서는 존재하지 않는 것과 같다. 요약 레이어가 곧 인덱스다.
heading-aware chunker, mergeShortChunks, wikilink auto-parser, Concept 허브 신설. 네 가지를 적용하고 다시 벤치마크를 돌렸다. links 테이블은 0에서 531로, content_chunks는 173에서 415로 늘었다. 정답률은 10/10이 됐다. 모델을 바꾸지도 인덱스 크기를 늘리지도 않았다. 결국 Karpathy 원칙을 정확히 지켰기 때문에 일어난 변화였다.
Drift는 감지가 아니라 구조로 막는다
같은 날 오후, 다른 방향에서 드리프트 하나가 더 나타났다. /worklog를 돌리다가 gbrain 관련 활동이 Projects/antiegg-server-agent(Vultr VPS 운영) 노트에 쌓이고 있는 것이 발견됐다. 두 도메인은 완전히 무관한데, 04-11에 gbrain 인프라 구축이 antiegg-server-agent의 확장으로 잘못 간주됐던 한 번의 오타가 7일간 조용히 증식한 것이다. Projects/gbrain.md를 신규로 만들어 OKR에 연결하고 이력을 옮겼다. 우연히 발견 안 했으면 drift는 계속됐을 것이다. commands/*.md와 skills/<name>/SKILL.md 페어를 sha256으로 비교하는 harness-drift-detector.mjs SessionStart 훅을 새로 짜서 감지 인프라를 한 겹 세웠다.
다만 감지로만 해결되지 않는 더 고약한 drift가 바로 이어서 드러났다. 같은 날 밤 새로 만든 critical-thinking.md 룰은 사용자 사실 주장을 검증 없이 reasoning chain의 전제로 채택하지 말라는 epistemic 가드레일이다. 이 룰 ship 직후 /worklog 실행에서 Claude Code가 "git-less 세션이니 Task 파생 없음"으로 1차 보고를 올렸다. "이건 task 파생 안 하는 게 맞는 거야?"라고 되물었다. 이 한 문장이 방금 만든 룰의 첫 적용 사례가 됐다. Claude는 룰이 시키는 대로 1차 소스를 열었다. 워크로그 스킬 SKILL.md line 150에 "단계 4.5 v2: 완전 커버리지"가 있었다. git-less 30분 이상이면 Task 파생, 스킵 룰 폐기. Claude의 1차 보고는 잘못된 판단이었다.
규칙이 안 보인 이유는 양방향 drift였다. Claude Code가 LLM에게 system-reminder로 넘기는 파일은 ~/.claude/commands/worklog.md(21KB, Apr 12)였는데 여기에는 단계 4.5의 구 버전이 들어 있었고, 최신 v2는 ~/.agents/skills/worklog/SKILL.md(31KB, Apr 14) 쪽에 있었지만 runtime 기준에서는 dormant 자료였다. 스킬을 개선할 때마다 commands 쪽은 갱신되지 않아 개선이 매번 dormant로 묻혔다. "지난 세션마다 개선해도 안 되는" 현상의 정확한 root cause였다.
해결은 by-construction이었다. commands/worklog.md를 백업하고 SKILL.md로 심볼릭 링크했다. 이제 두 경로는 같은 inode를 공유하고, drift가 발생하려면 누군가 의도적으로 rm + Write로 symlink를 깨야 한다. 일반 편집 경로로는 drift 자체가 불가능해졌다. 여기서 메타 루프 하나가 완성됐다. 무비판적 동의를 차단하려고 만든 critical-thinking 룰이 첫 적용 사례로 worklog 스킬의 숨은 drift를 드러냈고, drift가 symlink by-construction으로 닫혔다. 하나의 룰이 같은 날 안에서 자기 존재 이유를 증명한 셈이다. drift를 감지하는 것과 drift가 발생할 수 없게 만드는 것은 다른 문제다. 구조가 감지보다 앞선다.

4일이 남긴 것
지난 글의 주제는 "데이터가 레이어를 타고 흐르게 하라"였다. 쓰는 하네스에 관한 이야기였다. 4일을 지나고 나니 그것이 반쪽이었다는 것이 드러났다. 레이어를 흐르게 하는 것은 시작이고, 그 위에 읽히는 구조를 얹는 것이 다음 과제였다.
찾을 수 있는 구조는 세 가지 조건 위에서 성립했다. 첫째, 위키링크만으로는 흐릿한 기억을 못 잡으니 의미 검색 레이어가 필요하다. 둘째, 의미 검색 위에는 반드시 요약 레이어가 있어야 한다. Concepts는 사람이 읽는 문서가 아니라 LLM이 라우팅하는 테이블이고, retrieval 4/10에서 10/10으로 올라간 것은 모델이 강해져서가 아니라 이 구조를 지켰기 때문이다. 셋째, 아무리 잘 만들어도 호출이 일어나지 않으면 인프라는 dormant로 죽는다. 설치와 호출 사이에 구조적 연결이 있어야 실제로 동작한다.
drift도 같은 프레임으로 이해하게 됐다. 감지 인프라는 필요하지만 감지 가능한 drift는 이미 한 번 발생한 drift다. 구조적으로 불가능하게 만드는 쪽이 언제나 우선이다. 결국 4일이 보여준 것은 한 줄이다. raw는 있어도 요약이 없으면 찾을 수 없고, 레이어가 있어도 호출이 없으면 존재하지 않는 것과 같다. LLM 위키는 쓰는 하네스 하나로 끝나지 않는다. 쓴 것이 검색되고 호출될 수 있도록 읽히는 하네스까지 같이 설계해야 비로소 시스템이라고 부를 수 있다.

또 중요하게는, 다른 노드 링크를 관련성있다면 자연스러운 텍스트와 함께 무조건 넣게했어요. AI가 읽을때, 그 링크타고 들어가며 알아서 찾아지는게 장점이니까요.
저와 도메인이 달라 다를 순 있습니다.