CEO STAFF 에이전트의 온톨로지 구축기. 18개 PDF, 2회 인터뷰, 353개 사실에서 12개 문서까지.
AI 에이전트에게 "마케팅 전략 짜줘"라고 말하면, 범용 모델은 범용적인 답을 내놓는다. HubSpot 블로그에서 읽은 듯한 프레임워크, 어느 회사에나 적용 가능한 일반론이다. 회사의 누적 매출이 얼마인지, 고객 재구매율이 몇 퍼센트인지, 비즈니스 모델 전환을 준비 중이라는 것은 모델이 알 수 없다. 이런 정보의 상당수는 경영진의 머릿속, Slack 대화, 회의록 어딘가에 암묵지로 흩어져 있다. 에이전트가 회사를 이해하게 만들려면, 이 암묵지를 명시지로 바꿔서 구조화해야 한다. 온톨로지의 가장 큰 목적이 여기에 있다.
이전 회사 동료가 창업한 AI 스타트업의 경영을 돕게 됐다. 그 회사를 위한 CEO STAFF 에이전트를 설계하면서, 기업 지식을 체계적으로 정리할 필요가 생겼다. 온톨로지 공학은 전통적으로 지식 공학자나 데이터 사이언티스트의 영역이다. 하지만 LLM이 마크다운 문서를 읽고 추론할 수 있는 시점에, 형식적 온톨로지 대신 구조화된 사실 문서로도 유사한 효과를 낼 수 있다는 가설이 있었다. 결과적으로, 에이전트가 기업의 맥락을 정확히 반영한 응답을 내놓는 것을 확인하면서 이 접근이 유효하다는 확신을 얻었다. 회사의 모든 사실을 12개 문서로 구조화했다. 18개 PDF에서 시작해, CEO/CBO 인터뷰 2회를 거치고, Slack 22개 채널과 Notion 55개 페이지를 전수조사했다. 353개의 사실이 수집되고, 7개의 미확인 사항이 명시적으로 기록됐다. 이것이 온톨로지다. 이 글은 온톨로지를 쌓아가는 과정과, 그것이 에이전트 시스템에 어떤 차이를 만드는지를 기록한다.
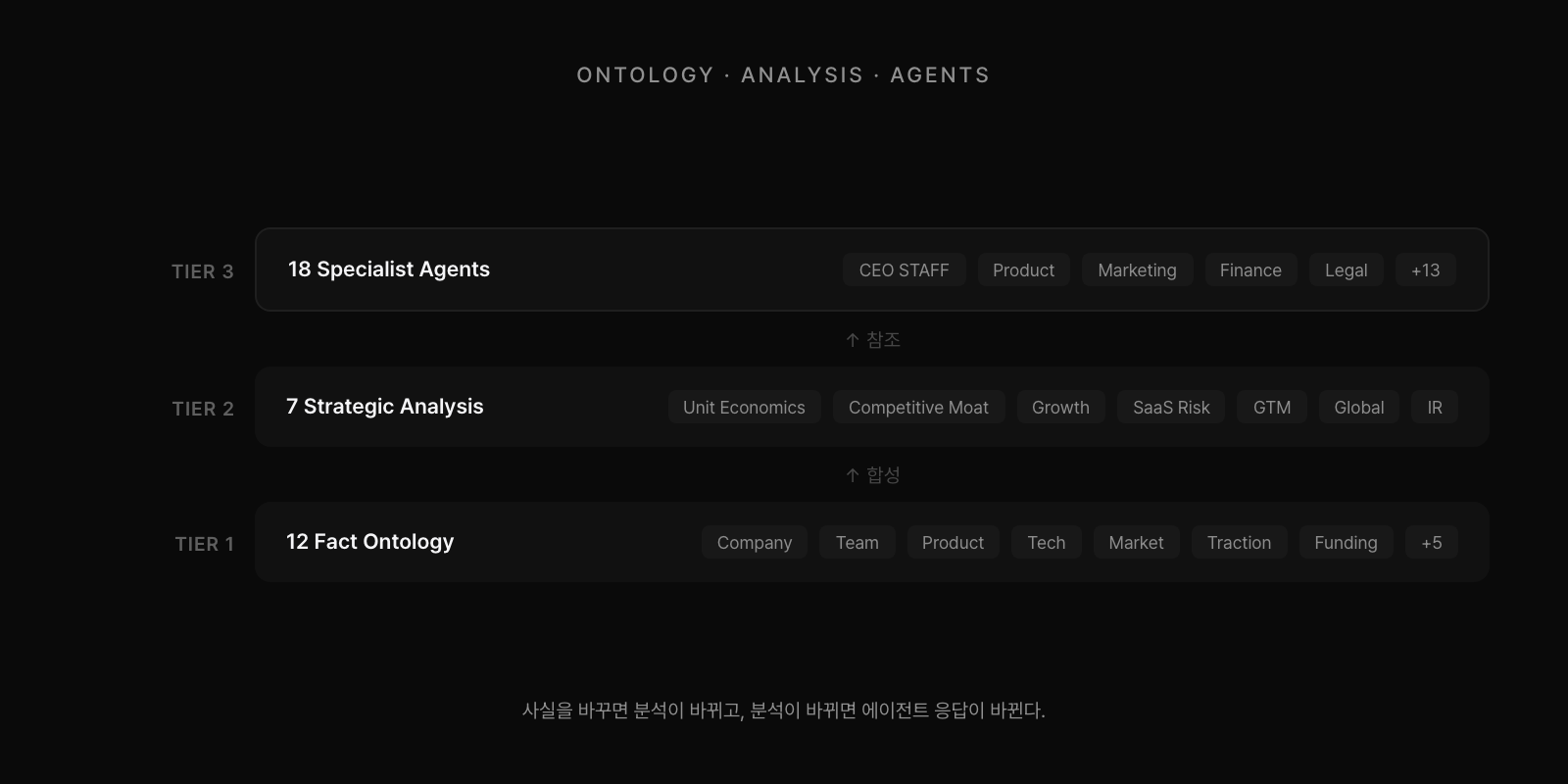
12개 문서로 회사를 담는다
온톨로지는 12개의 사실 문서로 구성된다. 01-company-overview부터 12-operations까지, 회사의 전 영역을 커버한다. 회사 개요, 팀 구조, 제품, 기술 스택, 시장, 트랙션, 펀딩, 로드맵, 고객, 브랜드, 글로벌 경쟁사, 내부 운영. 각 문서는 특정 시점(2026-03-10)의 사실을 담고 있으며, 추론이나 전망은 포함하지 않는다.
사실 위에 분석을 별도 레이어로 쌓았다. A01-unit-economics부터 A07-investment-readiness까지, 7개의 전략 분석 문서가 온톨로지의 사실을 기반으로 작성되었다. CAC/LTV 분석, 경쟁 해자 평가, 성장 진단, SaaS 전환 리스크, GTM 전략, 글로벌 확장, 투자 준비도. 각 분석 문서는 참조한 온톨로지 파일을 명시한다. 사실이 바뀌면 분석을 다시 생성하면 된다.
사실과 분석을 분리한 것이 이 구조의 핵심이다. 하나의 문서에 사실과 해석을 섞으면, 사실이 바뀌었을 때 어디까지 수정해야 하는지 알 수 없다. 분리하면 명확하다. 온톨로지는 "현재 상태가 무엇인가"를 답하고, 분석 문서는 "그래서 무엇을 해야 하는가"를 답한다. 이 두 질문의 답은 다른 주기로 바뀌고, 다른 과정을 거쳐 검증된다.
사실을 검증하는 4단계
온톨로지의 첫 번째 데이터 소스는 18개의 PDF였다. IR 덱, 사업계획서, 정부 지원사업 신청서. 창업 초기부터 축적된 공식 문서들이다. 여기서 회사 연혁, 제품 구조, 팀 구성, 재무 데이터의 기초 사실을 추출했다. 그러나 PDF만으로는 충분하지 않았다. 문서 간 수치가 일치하지 않는 경우가 있었고, 작성 시점의 계획과 현재 상태가 달라진 부분도 있었다.
두 번째 단계로 CEO와 CBO를 인터뷰했다. 1회차는 각각 독립적으로, 2회차는 함께 교차검증하는 방식이었다. 2회차 인터뷰에서 6건의 데이터 충돌이 해소됐고, 9개 온톨로지 문서가 업데이트됐다. PDF에서는 보이지 않던 의사결정의 맥락, 실패한 시도의 이유, 내부 역학 관계가 이 단계에서 드러났다.
세 번째 단계가 가장 규모가 컸고, 온톨로지의 핵심 목적인 암묵지의 명시지 전환이 본격적으로 이루어진 구간이다. Slack 22개 채널과 Notion 55개 페이지를 MCP(Model Context Protocol)로 연결하여 전수조사했다. PDF나 인터뷰에서는 포착되지 않는 종류의 지식이 여기에 있었다. 의사결정이 번복된 이유, 고객사와의 비공식 협의 내용, 팀 내부에서만 공유된 기술적 제약. 353개의 사실이 수집되어 raw-intelligence 디렉토리에 17개 마크다운 파일로 정리됐다. 이 중 120개가 경영진 검증을 거쳐 정식 온톨로지에 반영됐다. 나머지는 아직 검증이 필요한 상태로 원본 그대로 보존되어 있다. 네 번째 단계에서는 13개 글로벌 경쟁사와 APAC 시장을 웹 리서치로 조사하여 경쟁 맥락을 보강했다.
이 4단계를 거치면서 온톨로지는 3번의 대규모 갱신을 경험했다. PDF 기반 초기 버전, 인터뷰 후 버전, MCP 통합 후 버전. 각 단계가 이전 단계의 빈 곳을 채우고 오류를 교정했다. 검증 없이 한 번에 만든 온톨로지와, 4단계에 걸쳐 교차검증한 온톨로지의 품질 차이는 에이전트 응답의 정확도에 직접 영향을 미친다.

모르는 것을 기록한다
온톨로지 구축 과정에서 가장 중요한 판단은 "모르는 것을 어떻게 다룰 것인가"였다. 353개의 사실을 수집하고 나니, 7개의 미확인 사항이 남았다. 신규 서비스의 가격이 확정되지 않았다. 핵심 KPI의 수치가 두 출처에서 충돌했다. 활성 고객의 정의 기준이 부서마다 달랐다. 핵심 임원 채용이 진행 중이었지만 타임라인은 미정이었다.
이 미확인 사항들을 처리하는 방법은 두 가지가 있었다. 하나는 가장 그럴듯한 값을 골라서 온톨로지에 넣는 것이다. 다른 하나는 불확실성을 명시적으로 기록하고, 해소될 때까지 보류하는 것이다. 후자를 택했다. 7개의 블라인드 스팟을 별도 레지스터에 기록하고, 각각에 영향을 받는 분석 문서(A01, A04, A07 등)를 매핑했다. 해소 방법은 "CEO 인터뷰 3회차"로 예약됐다. 추정하지 않았다.
이 선택이 에이전트 품질에 직접 영향을 미쳤다. 에이전트가 "SaaS 가격 전략" 질문을 받으면, 가격을 가정하고 분석하는 대신 미확인 사항을 표면으로 올린다. "현재 복수의 가격 옵션이 병행 논의 중입니다. 확정된 내용이 있으신가요?" 이렇게 묻는다. 모르는 것을 기록하는 것이 아는 것을 기록하는 것만큼 중요한 이유는, 할루시네이션의 원천을 구조적으로 차단하기 때문이다.

에이전트가 온톨로지를 읽는 방식
CEO STAFF는 1명의 비서실장 에이전트와 17명의 전문가 에이전트로 구성된다. Product, Marketing, Finance, Legal 등 각 도메인의 전문가가 있고, CEO STAFF가 이들을 조율하는 허브 역할을 한다. CEO STAFF는 4개의 고유 스킬(IR Strategy, Strategic Briefing, Executive Operations, Product/Tech Advisory)을 보유하며, 다른 17개 에이전트가 필요할 때 이 스킬을 참조한다.
"시리즈A 투자 준비해줘"라는 요청이 들어오면, 라우팅 시스템이 CEO STAFF와 Finance 에이전트를 선택한다. 이 시점에서 읽히는 파일의 순서가 중요하다. 먼저 에이전트 시스템 프롬프트, 그 다음 관련 스킬 문서, 그 다음 사용자 피드백으로 축적된 지식 보정 파일, 마지막으로 온톨로지와 분석 문서가 읽힌다. 온톨로지 06-traction에서 누적 매출과 재구매율을 가져오고, 07-funding에서 런웨이와 자금 현황을 가져오고, A07-investment-readiness에서 투자 준비도 평가를 가져온다.
이 구조에서 온톨로지는 사전 로드되지 않는다. 요청이 들어왔을 때 필요한 문서만 읽힌다. 모든 에이전트가 12개 온톨로지 문서를 항상 메모리에 갖고 있는 것이 아니라, 라우팅 시점에 관련 문서를 참조하는 방식이다. 이 덕분에 에이전트는 가볍게 유지되면서도, 필요할 때 깊은 맥락에 접근할 수 있다. 온톨로지가 업데이트되면 별도 배포 없이 모든 에이전트가 즉시 새로운 사실을 기반으로 응답한다.
온톨로지를 쌓는 데 약 3주가 걸렸다. 가장 오래 걸린 것은 코드나 구조 설계가 아니라 사실의 검증이었다. PDF를 읽고, 인터뷰를 하고, Slack 로그를 뒤지고, 수치가 맞는지 교차확인하는 과정이 시간의 대부분을 차지했다. 이 경험에서 얻은 교훈은 단순하다. 에이전트의 품질은 프롬프트 엔지니어링이 아니라 사실의 품질에서 결정된다. 정확한 사실이 구조화되어 있으면, 프롬프트는 단순해도 된다.
