하네스 삼부작 ②. hashline 편집 시스템과 멀티에이전트 오케스트레이션의 결합.
AI 코딩 도구에 자율 실행을 기대하는 사람이 늘고 있다. "이 기능 만들어줘"라고 말하면 에이전트가 알아서 파일을 읽고, 코드를 쓰고, 테스트를 돌리고, 커밋까지 하는 그림이다. 그러나 이 그림에는 전제 조건이 있다. 편집이 정확해야 한다. 편집이 실패하면 에이전트는 재시도 루프에 빠지고, 사람이 개입해야 하고, 자율성은 사라진다.
이 글은 oh-my-hwclaude의 hashline 편집 시스템과 oh-my-claudecode(OMC)의 멀티에이전트 오케스트레이션이 결합하여 자율 실행의 기반을 만드는 과정을 다룬다. 편집 정밀도라는 가장 낮은 레이어에서 시작해서, 그 위에 오케스트레이션을 얹었을 때 무엇이 가능해지는지를 보여준다.
old_string이라는 병목
Claude Code의 기본 편집 도구인 Edit는 old_string 파라미터로 작동한다. 바꾸고 싶은 코드의 정확한 문자열을 넘기면, 파일에서 그 문자열을 찾아 new_string으로 대체한다. 원리는 단순하다. 문제는 "정확한 문자열"이라는 조건에 있다. 공백 하나, 탭 하나, 줄바꿈 하나가 달라도 매칭에 실패한다.
LLM이 코드를 생성할 때 원본의 공백을 완벽하게 재현하는 것은 구조적으로 어렵다. 토크나이저가 공백을 별도 토큰으로 처리하는 방식, 컨텍스트 윈도우 안에서 원본 코드가 멀어질수록 정확도가 떨어지는 현상, 그리고 들여쓰기 깊이가 깊은 코드에서 탭과 스페이스가 혼용되는 문제가 겹친다. Can Bölük의 벤치마크에서 str_replace 포맷의 편집 성공률이 6.7%까지 떨어진 것은 이 구조적 한계의 결과다.
편집이 실패하면 에이전트는 파일을 다시 읽고, 다시 old_string을 생성하고, 다시 시도한다. 이 루프가 한 번 돌 때마다 수백에서 수천 토큰이 소모된다. 5회 연속 실패하면 작업 하나에 수만 토큰이 낭비된다. 비용 문제만이 아니다. 재시도 루프 안에서 에이전트의 컨텍스트가 오염되고, 원래 의도와 다른 방향으로 편집이 수렴하는 경우도 발생한다. 편집 도구의 신뢰성이 낮으면, 에이전트가 아무리 똑똑해도 자율 실행은 불가능하다.

해시로 줄을 잡는다
oh-my-hwclaude의 hashline 시스템은 이 문제를 근본적으로 다른 방식으로 접근한다. 파일을 읽을 때 각 줄에 xxHash32 기반의 2문자 해시 태그를 붙인다. "4#WS|const count = 0" 같은 형식이다. 편집할 때는 old_string 대신 이 태그로 위치를 참조한다. 원본 코드를 한 글자도 재현할 필요가 없다.
해시는 줄의 내용을 검증하는 역할도 한다. 편집 요청이 들어오면, 지정된 줄의 현재 해시와 요청의 해시를 대조한다. 일치하면 파일이 읽은 시점 이후로 변경되지 않았다는 의미이므로 편집을 실행한다. 불일치하면 파일이 변경되었다는 의미이므로 재읽기를 안내한다. 문자열 매칭이 아니라 해시 검증이기 때문에 공백이나 탭의 차이로 실패하는 일이 원천적으로 사라진다.
구현에도 의도적인 선택이 있다. xxHash32를 순수 TypeScript로 구현해서 네이티브 의존성을 없앴다. 해시 결과를 256개 딕셔너리("ZP", "MQ", "VR" 등)로 매핑해서 LLM이 해시를 "읽을 수 있게" 만들었다. 빈 줄에는 줄 번호를 시드로 넣어 동일한 빈 줄끼리 구분되도록 했다. 그리고 6가지 자동 보정(autocorrect) 파이프라인을 추가했다. LLM이 해시라인 접두사를 대체 텍스트에 포함시키거나, diff 마커를 넣거나, 들여쓰기를 날리거나, 여러 줄을 하나로 합치는 실수를 자동으로 감지하고 수정한다. 도구 자체가 LLM의 실수 패턴을 알고 대응하는 구조다.
실패를 가정한 설계
hashline이 편집 성공률을 크게 올리지만, 100%는 아니다. 중요한 것은 실패했을 때 시스템이 어떻게 반응하는가다. oh-my-hwclaude는 6종의 훅으로 실패에 자동 대응한다. pre-tool-use 훅은 기본 Edit 도구 사용을 감지해서 hashline_edit을 안내하고, 기존 파일에 Write를 시도하면 차단한다. post-tool-use 훅은 해시 불일치를 감지하면 자동으로 재읽기를 안내하고, JSON 파싱 에러에는 수정 방법을 주입한다. 서브에이전트 시작 시에는 hashline 사용법을 자동 주입해서, 하위 에이전트도 같은 워크플로우를 따르게 한다.
더 흥미로운 것은 5계층 게이트키핑 시스템이다. 같은 실수가 반복되면 자동으로 강도가 올라간다. 처음에는 대화 안에서 수정한다(L0). 같은 실수가 2회 발생하면 knowledge 파일에 등록된다(L1). 3회 이상 무시되면 rules 파일로 승격된다(L2). 규칙까지 위반하면 훅으로 코드 레벨에서 강제한다(L3). 최종적으로는 도구 설계 자체가 올바른 방식만 허용한다(L4). 실수 로거가 모든 에러를 JSONL 파일에 기록하고, 에스컬레이션 프로토콜이 패턴을 감지해서 자동으로 상위 레이어로 올린다.
이 구조의 핵심은 "실패가 시스템을 강화한다"는 원칙이다. 한 번 발생한 실수는 기록되고, 반복되면 자동으로 방지 메커니즘이 생긴다. 시간이 지날수록 시스템이 단단해진다. 사람이 매번 같은 문제를 알려줄 필요가 없어진다.

오케스트레이션이 더해지면
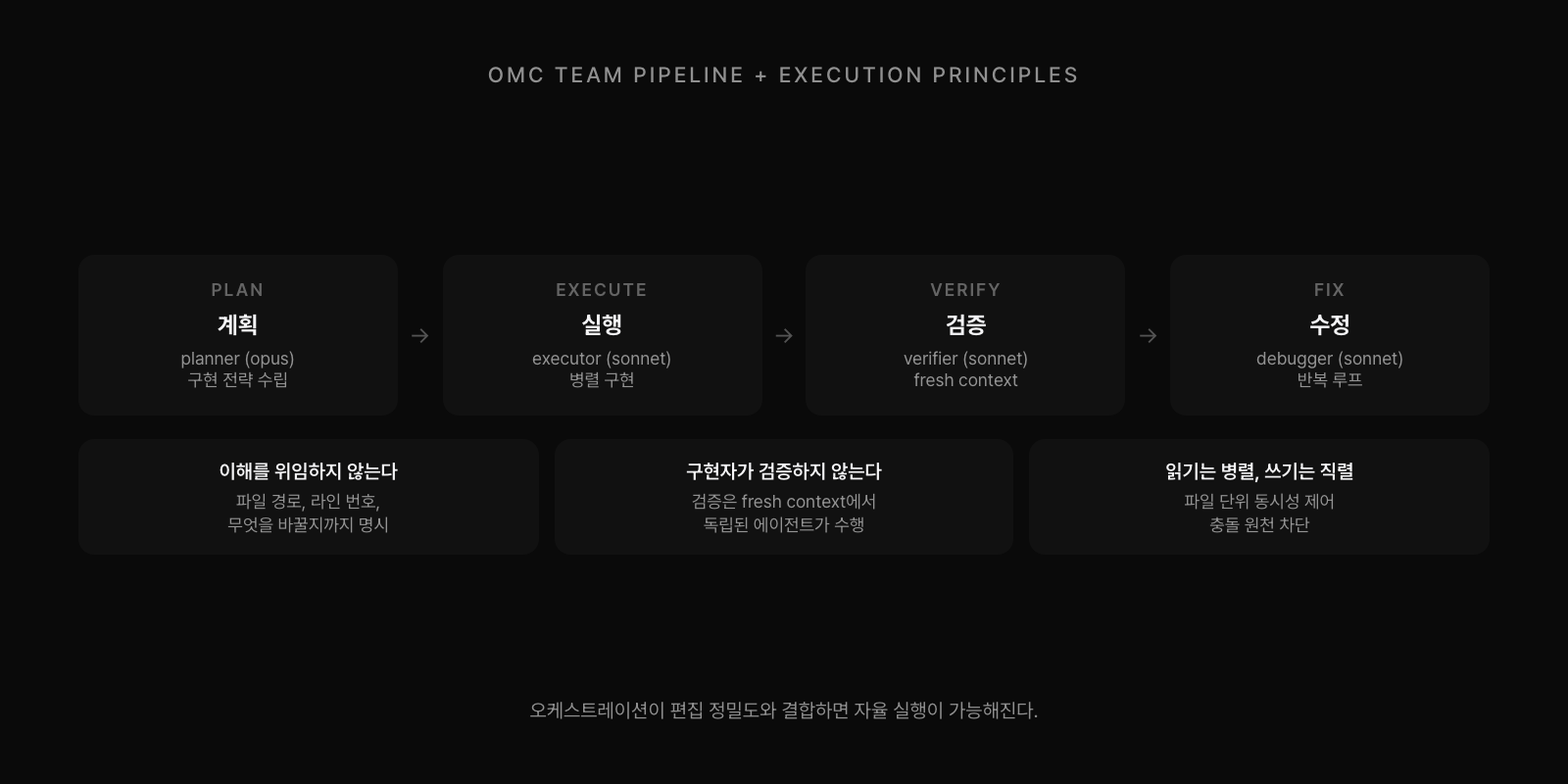
hashline과 자동 복구가 편집의 신뢰성을 보장한다면, oh-my-claudecode(OMC)는 그 위에서 "누가, 어떤 순서로 편집할 것인가"를 관리한다. OMC의 팀 파이프라인은 plan → execute → verify → fix 순서로 작업을 진행한다. planner(Opus)가 전략을 세우고, executor(Sonnet)가 병렬로 구현하고, verifier(Sonnet)가 fresh context에서 독립 검증하고, 문제가 발견되면 debugger가 수정한다.
여기서 중요한 원칙이 세 가지 있다. 첫째, "이해를 위임하지 않는다(Never delegate understanding)." 코디네이터는 서브에이전트에게 "알아서 해"라고 맡기지 않는다. 파일 경로, 라인 번호, 무엇을 바꿔야 하는지까지 구체적으로 명시한다. 둘째, 구현자가 자기 코드를 검증하지 않는다. 검증은 구현 과정을 모르는 fresh context에서 실행된다. 확증 편향을 구조적으로 차단한다. 셋째, 읽기 작업은 자유롭게 병렬로 실행하되 쓰기 작업은 파일 단위로 직렬 처리한다. 파일 시스템 레벨의 동시성 제어를 에이전트에게 적용한 것이다.
이 오케스트레이션이 hashline 편집과 결합하면 자율 실행의 기반이 만들어진다. planner가 작업을 분해하고, executor가 hashline_edit으로 정확하게 편집하고, 편집이 실패하면 자동 복구 훅이 대응하고, verifier가 결과를 검증한다. 사람이 개입해야 하는 지점이 대폭 줄어든다. autopilot이나 ultrawork 같은 OMC의 자율 실행 모드가 실제로 작동할 수 있는 것은, 그 아래에서 hashline이 편집의 신뢰성을 보장하고 있기 때문이다.
결국 자율성은 추상적 개념이 아니다. 편집 성공률, 실패 복구 속도, 검증 독립성 같은 구체적인 지표들의 합이다. 하네스의 각 레이어가 이 지표들을 하나씩 올려주고, 그 누적이 "사람이 빠져도 돌아가는 시스템"을 만든다. 다음 편에서는 이 기반 위에 도메인 전문성을 구조화한 business-ai-team의 이야기를 다룬다.