AI:MED의 뉴스레터에 발행된 글입니다.
디지털 헬스, 바이오테크, 인공지능 기술이 의료를 어떻게 바꾸고 있는지, 어떤 실험과 도전이 일어나고 있는지, 현실과 미래 사이의 이야기의 핵심만 뽑아 전달하는 뉴스레터 AI:MED를 구독하면 더 빠르게, 더 다양한 이야기를 전달받을 수 있어요 🚀
최신 AI 모델 ‘GPT-5’가 8월 7일(현지시각)에 공개가 됐죠. OpenAI의 CEO 샘 알트먼은 “GPT-5와 대화하면 박사급 전문가와 대화하는 것과 같은 느낌을 받을 수 있다”고 말하며 “의료/헬스케어 분야에서 큰 도움을 줄 수 있을 것”이라고 자신있게 말합니다. 그가 이렇게 자신있게 말할 수 있는 이유는 GPT-5의 성능 지표가 실제 수치상으로 크게 개선되었고, 특히 의료 분야 성능과 안전성을 평가하기 위한 자체개발 벤치마크인 HealthBench에서도 좋은 성적을 거뒀기 때문입니다.
이번 아티클에서는 GPT-5가 의료 분야에서 어떤 성능을 보이고 있는지 HealthBench의 지표들을 하나씩 살펴보는 시간을 가져보도록 하겠습니다 🚀
HealthBench
HealthBench가 뭔가요?
HealthBench는 OpenAI가 2025년 5월 12일에 발표한, 헬스케어 분야를 위한 AI 성능 및 안전성 평가 벤치마크입니다. 기존의 AI 의료 벤치마크는 대부분 객관식 문제를 푸는 방식으로 성능을 평가했다면, HealthBench는 다양한 의료 현장의 시나리오를 바탕으로 모델을 평가하도록 설계되었어요.
여기서 “시나리오”란, 환자가 증상을 설명하고, 의사가 추가 질문을 하고, 치료 방안을 안내하는 실제 진료 흐름을 뜻해요. 즉, “이 약물의 부작용은?”, “이 질환의 치료법은?” 같은 질문이 아니라, 환자와 의사가 주고받는 대화를 그대로 재현한 것이죠. 참고로, 실제로 의사 면허시험의 필기시험은 객관식 문항으로 이루어지지만, 실기시험은 모의 환자와 직접 대화화며 문진 - 증상 파악 - 신체진찰 - 진단추론 - 처치 및 치료안내 - 환자 교육 과정을 거쳐 점수를 합산하는 방식으로 이루어진답니다.
HealthBench는 전 세계 60개국, 262명의 의사가 직접 참여하여 5,000개에 달하는 대화 시나리오를 만들었다고 합니다. 또한, HealthBench는 다시 고난도 문제 1,000개로 이뤄진 'HealthBench Hard'와 의사 합의 평가 항목들로 구성된 'HealthBench Consensus' 등 2개의 보조 벤치마크도 존재하는데요, 이번 GPT-5의 성능평가 지표에는 이 3가지 지표 모두에서 개선된 점을 보입니다.
아래는 HealthBench 시나리오의 7가지 테마입니다.

HealthBench의 평가방식 : 루브릭
HealthBench는 의사들이 직접 참여해 만든 루브릭(Rubric)이라는 평가방식을 적용하여 점수를 산출합니다. 위에 소개된 7가지 테마에 대해 시나리오를 진행하고, 이 대화를 바탕으로 정확성·완전성·문맥 인지·지시 따르기·소통 품질의 5가지 축으로 성능을 분석합니다.

각 예시에 대해 루브릭의 항목별로 만점/0점(또는 패널티)를 부여해 합산하고, 가능한 최대점에 대한 비율로 환산합니다. 항목은 +10부터 −10까지 배점이 있고(금지·주의 사항은 음수), 모델 기반 그레이더가 항목별 충족 여부를 독립적으로 판단합니다. 이 과정을 모든 예시에 적용해 평균을 내 최종 점수를 만듭니다.
GPT-5 이전의 HealthBench 결과는 어땠을까?
OpenAI에서는 현재까지 나온 인공지능 모델들의 HealthBench 결과를 공개하고 있는데요, 우선 이번 GPT-5의 결과를 살펴보기 이전에 기존의 결과들을 한 번 보겠습니다. GPT-5 성능 결과가 궁금한 분들은 바로 아래로 내려가주세요 -! 👇🏻
테마별 점수
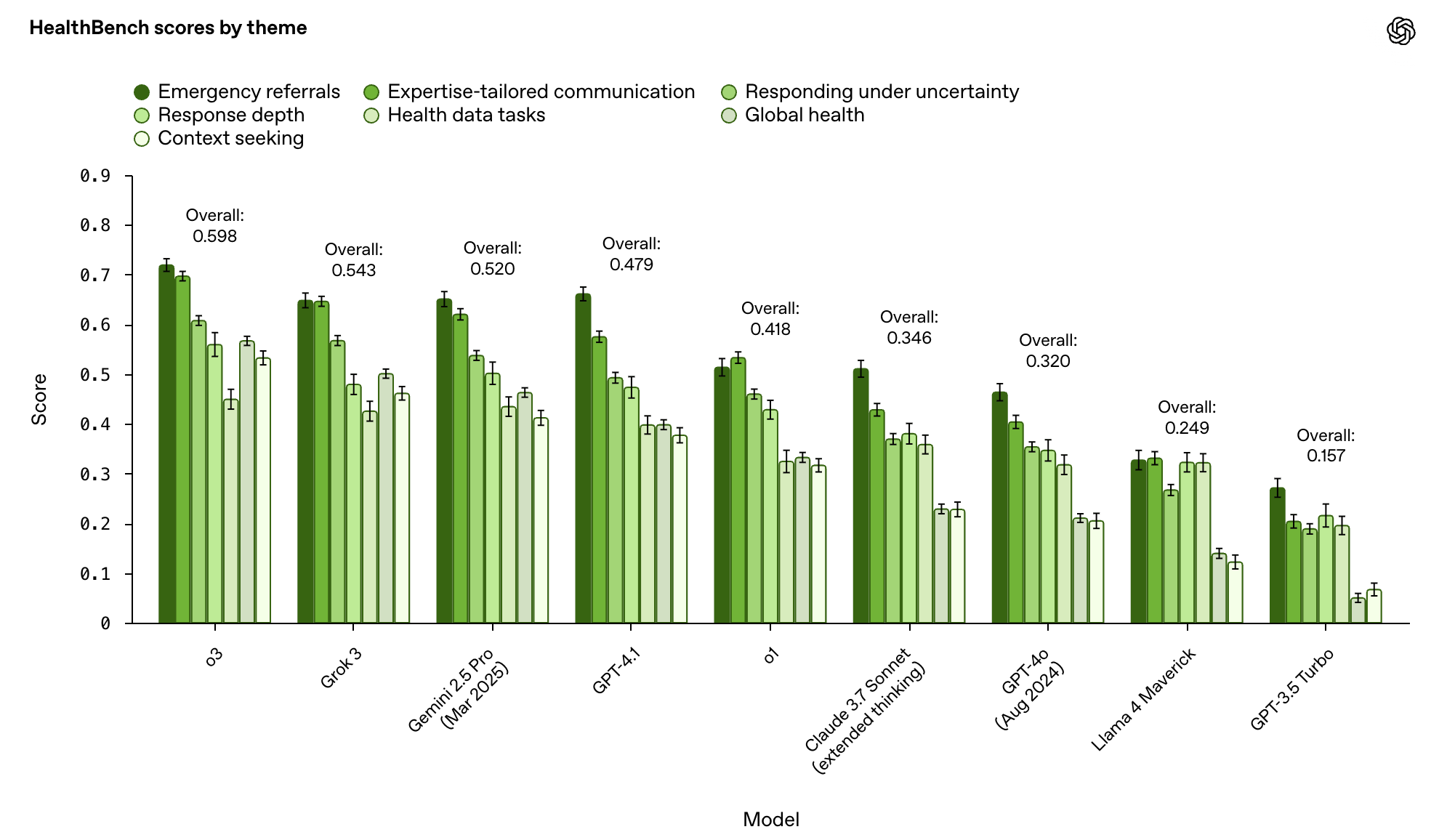
GPT-5 이전까지는 o3의 성능이 높은 것을 볼 수 있습니다. 그 뒤로 Grok 3와 Gemini 2.5 pro가 따라오고 있는 모습입니다.
의사의 답안과 비교 결과
아래의 그래프는 “AI가 임상의 기준과 얼마나 비슷하거나 다른가”를 보기 위해 의사가 직접 쓴 모범 답안과 모델 답안을 축(정확성·완전성·문맥 인지·지시 준수·소통)별로 비교한 결과입니다. 일부 의사그룹은 인터넷만 활용했고, 다른 의사그룹은 모델의 참고답안을 전달받아(복사·수정 포함) 답변을 다시 작성하는 과정을 거쳤습니다.
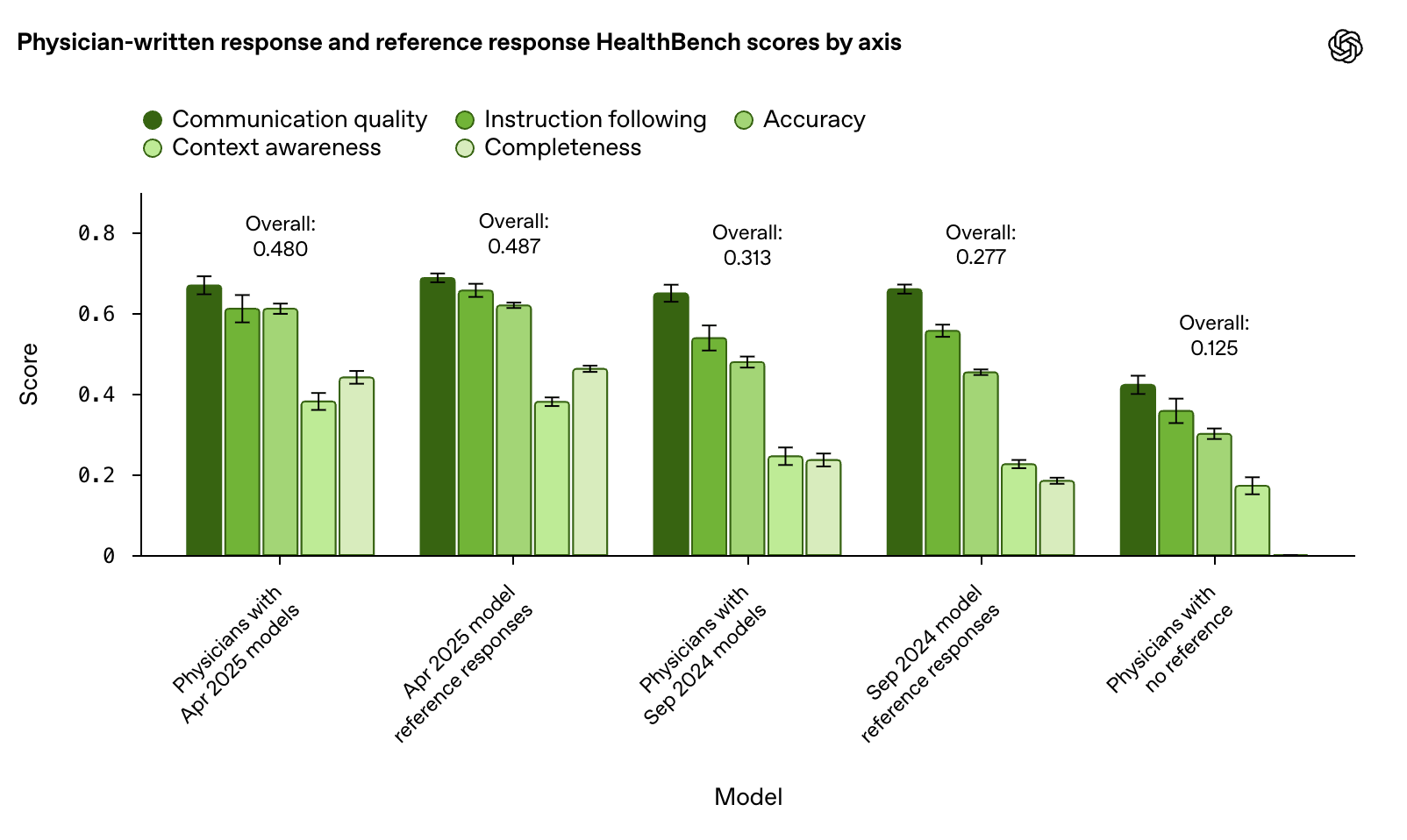
2024년 9월 모델(o1-preview, GPT-4o) 단계에선 모델 참고+의사 보정이 모델 단독 참고답안을 분명히 앞섰고(Overall 0.313 vs 0.277), 두 그룹 모두 의사 단독보다는 좋았습니다(0.125). 반면 2025년 4월 모델(o3, GPT-4.1에서는 의사 보정이 더해져도 모델 참고답안을 더 이상 개선하지 못했고, 오히려 모델 단독 점수(0.487)가 의사 보정(0.480)과 동급 이상이었습니다.
💡 최신 모델은 이미 의사가 수정/보완을 하는 것이 큰 의미가 없을 만큼 기준 답안의 품질이 높아졌다는 점을 제시하고 있네요.
GPT-5 HealthBench 성능, 핵심만 보기!
무엇이 좋아졌나요?
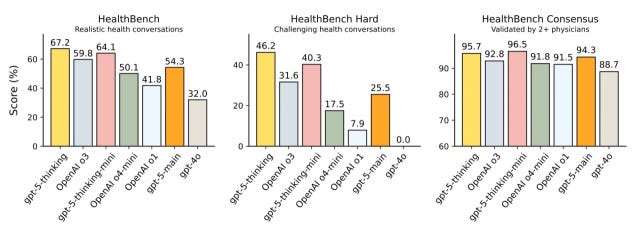
GPT-5 시리즈는 추론형 모델인 'Thinking'이 일상적인 의료 상담과 건강 지식을 다루는 HealthBench에서 67.2%의 점수를 보이면서 기존 GPT-4 시리즈의 모든 모델을 전반적으로 상회합니다. 지금까지 가장 범용적으로 쓰인 GPT-4o가 획득한 점수 32.0%과 비교하면 2배 이상 개선된 점을 볼 수 있죠.
고난도 문제와 전문적인 의료 시나리오를 다루는 HealthBench Hard의 결과를 볼까요? GPT-4o는 0.0%이었는데, GPT-5 Thinking은 46.2%를 기록합니다.
마지막으로 의사 전문가 집단의 판단과 유사성을 평가하는 HealthBench Consensus에서는 GPT-5 시리즈의 가장 작은 모델인 GPT-5 Thinking-mini가 96.5%로 최고점을 받았고, GPT-5 Thinking이 95.7%를 기록합니다.
💡 의사와의 판단 유사성 지표에서는 대부분 모델이 90% 이상의 높은 점수를 기록하고 있네요.
환각(Hallucination) 및 오류(Errors) 개선
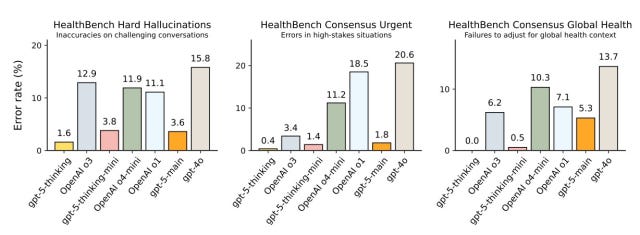
GPT-5 Thinking은 HealthBench Hard에서 오류율 1.6%로 o3 대비 8배 감소했고, HealthBench Consensus의 긴급상황(고위험상황)에서의 안내 오류율은 0.4%로 o3대비 8배 감소했습니다. HealthBench Consensus의 글로벌 보건 환경에 따른 맥락 조정 실패율은 0.0%로 측정이 전혀 되지 않았네요.
HealthBench와 루브릭 평가 체계의 한계
이번 벤치마크 점수의 향상은 이전 모델들과 비교해 높은 성과를 보여줬습니다.
다만, HealthBench는 5,000개의 달하는 방대한 의료 현장 시나리오를 포함하고 있지만, 실제 의료 현장을 완벽히 재현하지는 못합니다. 이러한 시나리오들은 예측 가능하고 통제된 상황만을 제안하고 있습니다.
또, 실제로 HealthBench를 소개하는 정식 논문에서도 루브릭 채점 방식의 모호함(상이한 기준, 신뢰성이 검증되지 않는 개별 예시), 실제 병원 현장에서의 적합도 등을 보장할 수 없다고 말합니다.
마무리하며
GPT-5의 HealthBench 성능에 대해 간략히 알아보았습니다 👐🏻
앞으로 의료 영역에서 AI의 활용도가 점점 더 높아질 것이라는 기대감이 생기는데요! 혹자는 인공지능이 빠른 시일 내에 의사의 업무를 대체할 수 있을 것이라고 주장하기도 합니다. 실제로 통제된 환경과 시나리오 기반의 성능평가에서 의료인에 필적하는 성능을 보여준 것은 사실이죠.
하지만, 아직 기계로 대체하기 어려운 과업이 많고 숙련된 전문의료인의 감독이 필요한 의료현장의 상황을 모두 대체하기는 정말 어렵기 때문에 단기적으로는 의사의 역량을 강화하고, 업무효율을 증가시켜 진단 및 치료의 질을 높이는 방향으로 더 큰 도움이 될 수 있을 것이라는 생각이 듭니다.
* 본문에 활용된 도표와 그래프는 전부 OpenAI 공식 홈페이지 - Introducing HealthBench 및 GPT-5 System Card에서 발췌하였습니다.
