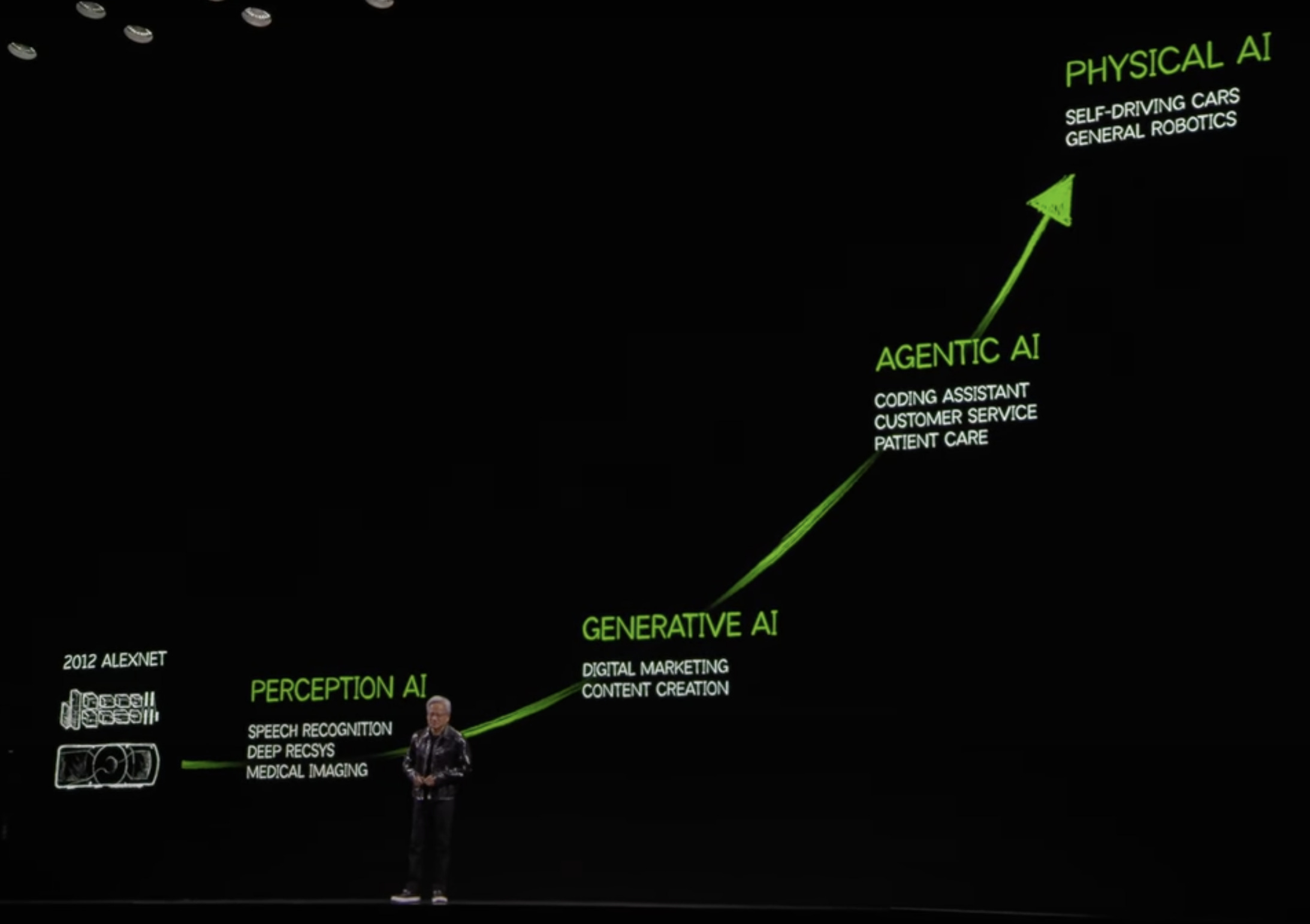
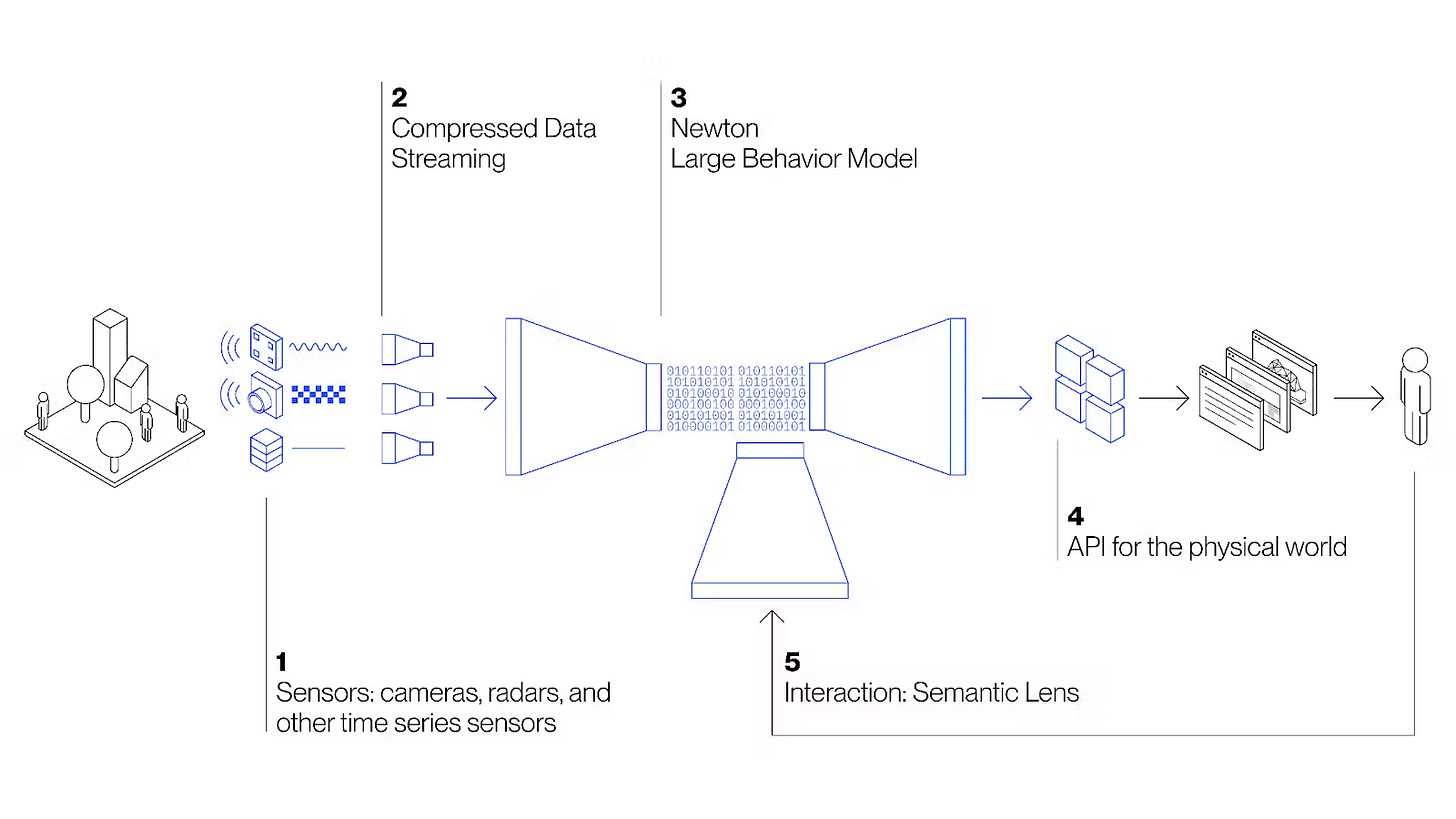
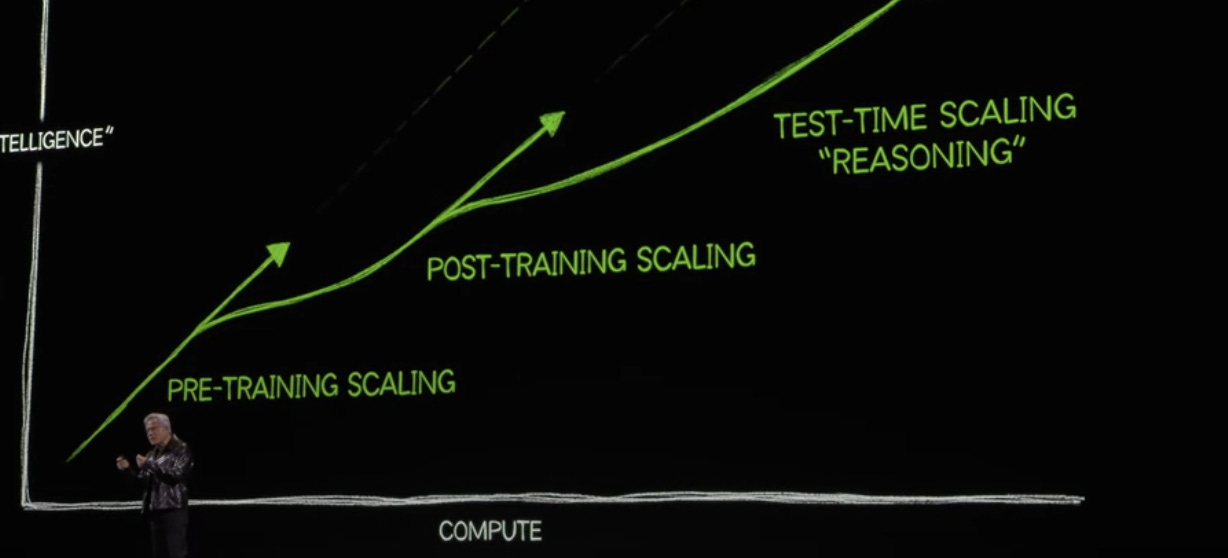
Physical AI의 성장과 관련한 산업분야에 대한 이야기를 들어보면 대부분이 AI 반도체, 로보틱스, 데이터센터가 주를 이루고 있습니다. 모두 흥미로운 분야이지만, 저는 특히나 ‘물리세계의 데이터를 어떻게 학습시킬 것인가’ 해당 주제에 더욱 관심이 갔습니다. 특히, 최근 레거시한 산업분야를 돌아보면서, 그저 쌓이기만 하던 데이터가 이제는 자산이 되고 있으며 앞으로 기업은 적재되는 히스토리와 휘발성 데이터를 자산 가치로 만드는가는 굉장히 중요한 문제입니다. 또한 이제는 물리세계에서 벗어나 시뮬레이션 세계를 통해 물리세계를 재구현하고 있습니다. 이번 뉴스레터는 다가올 미래 Generative Physical AI의 Operation 데이터 학습과 물리세계를 재구성하는 시뮬레이션, 디지털트윈 생태계와 로보틱스에 대해 알아보겠습니다.
❶ 제조·유통·농업·(외 국방 등): 산업규모와 레거시한 문제들
거대 규모 시장의 변화
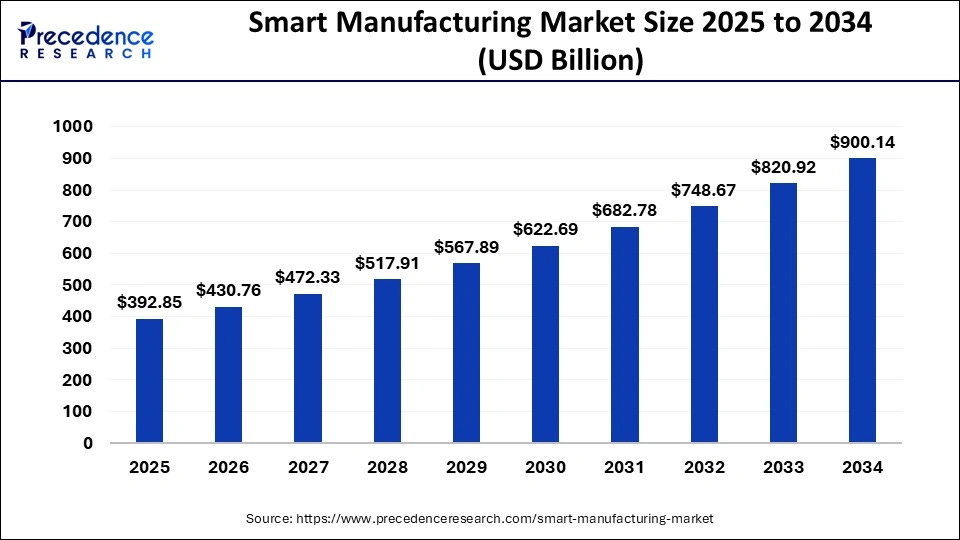
제조: 거대한 시장 규모와 스마트 제조로의 전환
글로벌 제조업 시장은 2025년 14.85조 달러 규모로 평가되며, 2032년까지 20.76조 달러에 도달할 것으로 예상되어 CGAR 4.9%의 성장률을 가진 거대한 시장입니다. 특히 Smart Manufacturing 시장은 더욱 급속한 성장을 보이고 있어, 2025년 3,928억 달러에서 2034년 9,001억 달러로 연평균 9.65%의 높은 성장률을 기록할 것으로 예상됩니다.
1차 산업 시장의 규모는 세계 경제를 지탱할 정도로 거대하지만, 이 레거시한 산업구조를 바꾸기란 쉽지 않습니다. 그러나 AI 라는 새로운 시대가 레거시 산업의 전반을 뒤흔들 것이라는 기대감이 시장에 차오르고 있는 것입니다.
"Physical AI will revolutionize the $50 trillion manufacturing and logistics industries. Everything that moves — from cars and trucks to factories and warehouses — will be robotic and embodied by AI.”
-젠슨 황-
레거시 문제들과 공통된 병목 현상
예측 불가능한 다운타임: 예상치 못한 장비 고장으로 인한 생산 중단
품질 불일치: 수작업 기반 품질 관리로 인한 편차 발생
에너지 비효율: 최적화되지 않은 생산 프로세스로 인한 에너지 낭비
재고 관리 비효율: 수요 예측 부정확으로 인한 과잉/부족 재고
숙련 인력 의존: 베테랑 작업자의 경험과 직관에 의존하는 생산 프로세스
복잡한 공급망 관리: 다단계 공급망에서의 가시성 부족
창고 운영 비효율: 수작업 기반 창고 관리 시스템
반품 처리 복잡성: 역물류 프로세스의 비효율성
유지보수 비효율: 예측 정비 부족으로 인한 높은 유지비용
노동자 안전 위험성: 특히 위험 사고 발생율이 높음
이 밖에도 ROI의 불확실성, 레거시 사일로 조직으로 인한 의사결정 지연, 산업별·기업별로 상이한 시스템과 프로토콜로 인해 체계적으로 통합되지 못한 환경에서 예상치 못한 손실이 대규모로 발생하고 있습니다.
❷ 어떻게 해결할까? : Generative Physical AI
일반적으로 Physical AI는 인공지능 + 물리적 로봇과 결합된 시스템을 말합니다. 조금 더 엄밀히 정의하면, 센서 + AI 워크로드(ML/DL, NLP 등) + 액추에이터로 결합된 시스템입니다. 센서를 통해 세계를 관찰하고, AI를 통해 판단하고 결정하며, Actuator를 통해 세계와 상호작용할 수 있습니다.
Physical AI의 적용 범위는 매우 광범위합니다. 전통적인 산업용 로봇부터 서비스 로봇, 자율주행 차량, 드론, 협동로봇(cobot), 휴머노이드에 이르기까지 다양한 형태의 지능형 로봇이 모두 포함됩니다.
기존의 로봇 시스템이 미리 정해진 프로그램에 따라 반복 작업만을 수행하는 고정 자동화 방식이었다면, Physical AI 시대의 로봇은 근본적으로 다릅니다. 머신러닝과 딥러닝 기술을 통해 환경을 실시간으로 인식하고 학습하며, 상황에 따라 임무를 유연하고 적응적으로 수행할 수 있습니다.
Generative Physical AI는 물리적 환경과 상호작용하는 자율 시스템을 구축하기 위해 Perception(지각)-Reasoning(추론)-Action(행동)의 3단계 아키텍처를 채택합니다.
지각 단계 : LiDAR·레이더·IMU(관성측정) 등 멀티모달 센서가 주변환경에 대한 데이터 포인트를 수집합니다.
추론 단계 : NVIDIA Jetson AGX Orin과 같은 엣지 컴퓨팅 장치가 높은 처리 성능으로 실시간 의사결정을 수행합니다. 이는 마치 사람의 뇌가 상황을 파악하고 결정을 내리는 것과 유사합니다.
행동 단계 : 정밀한 로봇 팔이 매우 세밀한 작업을 수행할 수 있습니다. 머리카락 굵기만큼 정확한 움직임이 가능하여 복잡한 물체 조작 작업을 할 수 있습니다. (ex: KUKA + MIRAI)
이러한 과정은 Robot Operating System 기반의 개방형 소프트웨어 생태계에서 표준화된 시스템으로 굳어지고 있습니다.
우리는 결국 전통 산업의 휘발성 데이터를 어떻게 수집 및 학습시킬 것인가 라는 문제에 봉착하게 됩니다. 전통 산업에서는 데이터가 불규칙하게 발생하고, 고장이나 이상 상황 같은 중요한 사건은 예측하기 어려우며, 전문가의 도메인 지식이 필요한 복잡한 환경적 요인들이 많습니다. 우리가 가진 것은 과거 데이터이고, 과거를 기반으로 미래를 추론할 능력이 필요합니다.
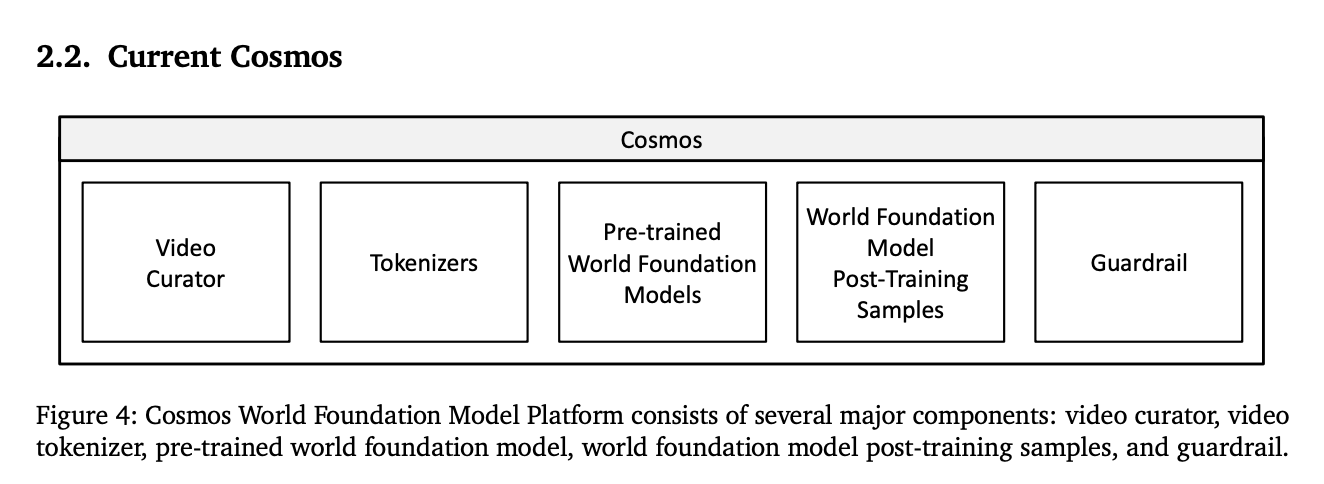
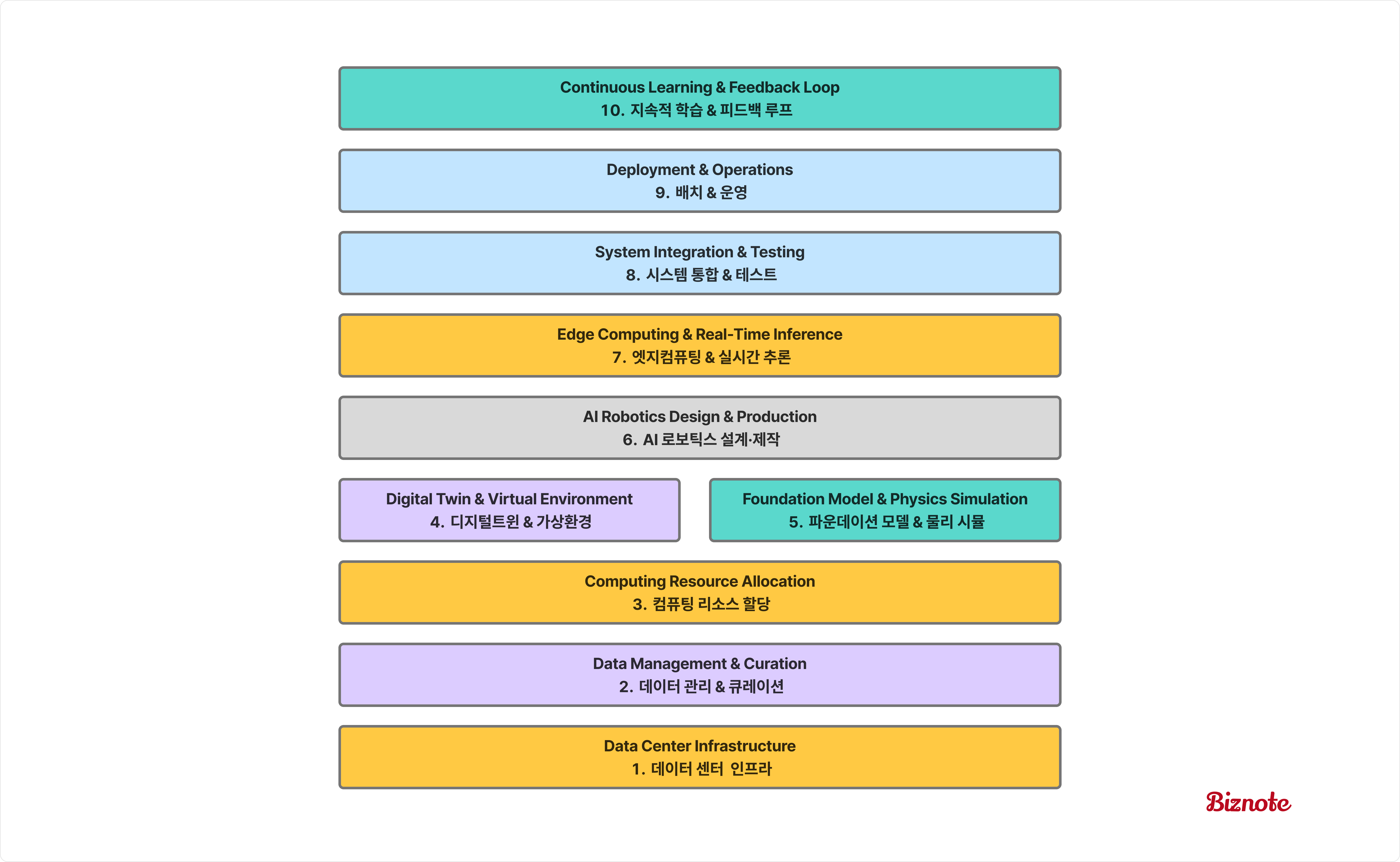
Physical AI 3계층 프레임워크
각 계층을 거치며 Training → Simulation → Deployment의 플라이휠로 학습루프를 진행합니다
- Training computer : WFM과 물리 시뮬레이션 모델 개발
- Simulation computer : 디지털 트윈 기반 AI 모델 최적화
- Deployment computer : 물리 환경에서 최적화된 모델 실행
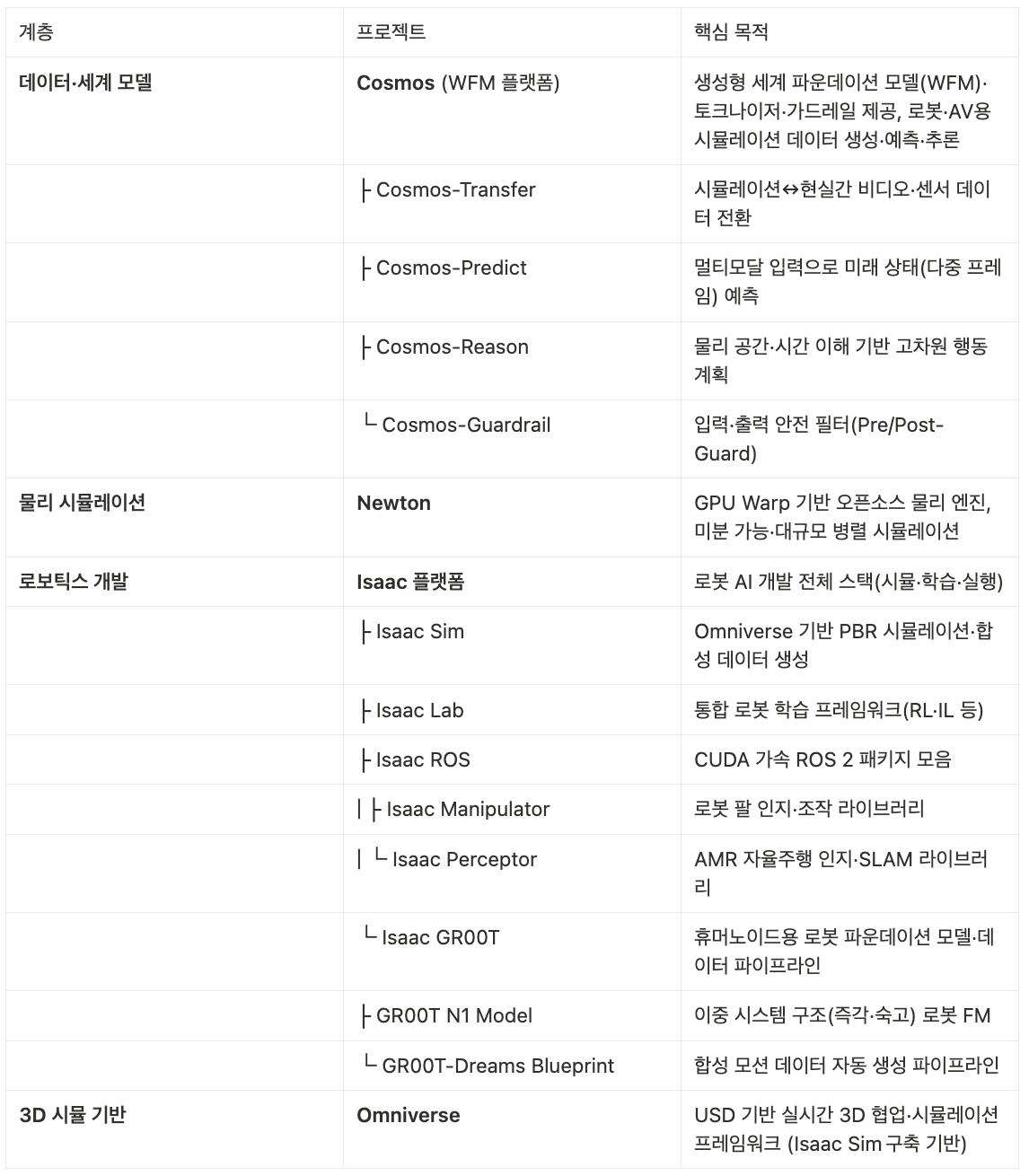
월드 파운데이션 모델(WFM)
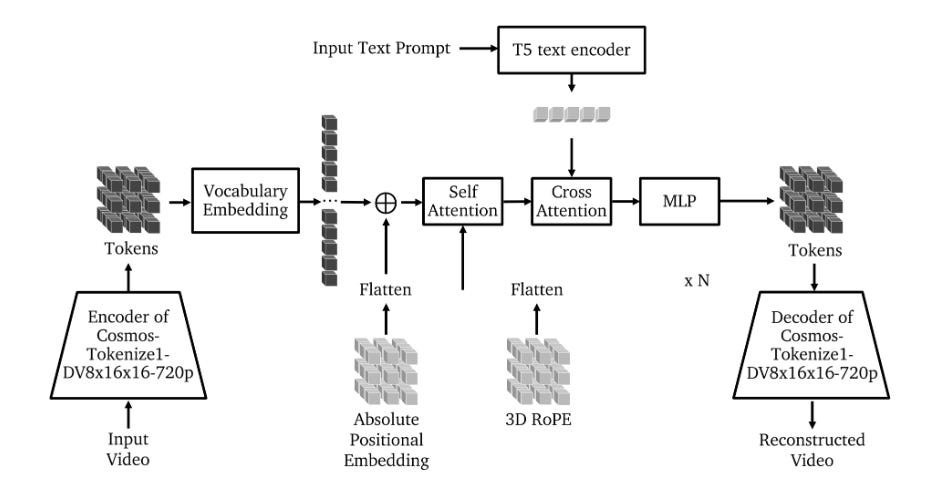
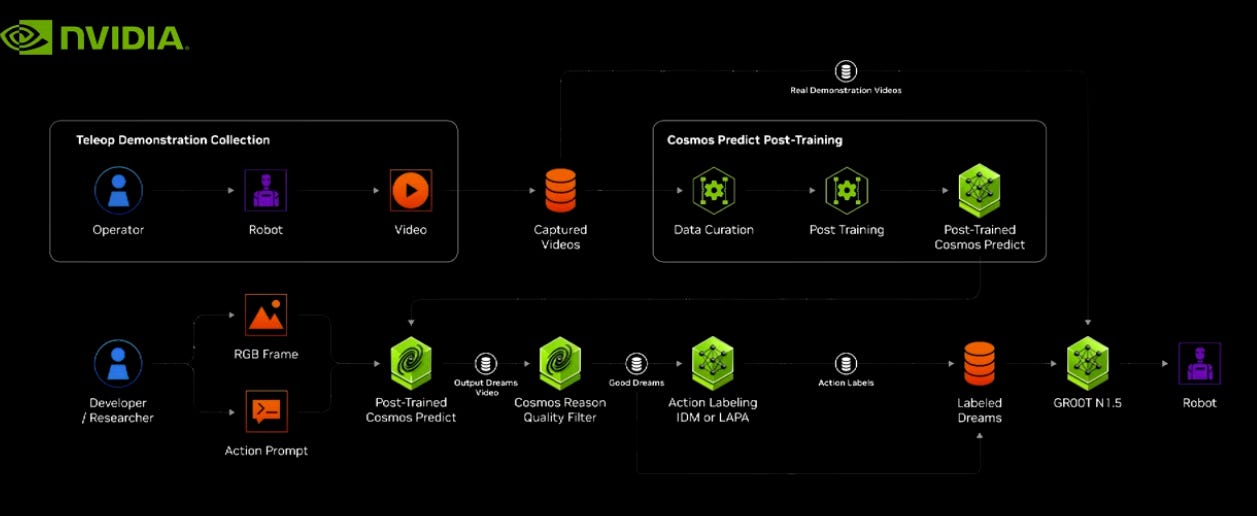
최신 Physical AI Foundation 모델 분야를 선두하는 기업, NVIDIA는 VLM(Visual Language Model) 기반 데이터 학습으로 사전/사후 데이터 학습을 통한 산업별 Physical AI 구축 플랫폼을 데이터 학습모델의 기저로 가져가고 있습니다. 이 모델은 Robotics를 위한 파운데이션을 넘어 물리세계를 학습하고 미래를 예측하는 모델을 지향하고 있습니다. WFM은 비디오를 잘게 나누어 토큰화 하고 사전 학습 시키며, 공장 또는 물리 환경에 맞는 Custom Dataset 기반으로 사후 학습을 시켜 오차율을 줄이고 상황에 유동적인 학습 방법을 제시합니다.
엔비디아의 Cosmos 플랫폼은 AI 학습을 위한 파운데이션 모델과 학습 방법론을 제시합니다. Video 데이터를 잘게 잘라 text prompt와 함께 과거 데이터를 기반으로 미래를 추론하는 비디오 셋트를 생성합니다. 액추에이터는 학습 모델을 기반으로 추론하여 액션할 수 있습니다.
사전 학습(Pretraing)
자기 회귀 모델을 활용하여 빠르게 미래 시퀀스에 대한 토큰을 생성한 후, 확산 회귀를 기반으로 디코더를 통해 화이트 노이즈를 제거하며 선명한 비디오를 생성합니다.
<자기 회귀, autoregressive-based WFM>
자기회귀 모델은 어려운 생성 문제를 다음 토큰 예측 문제의 시퀀스로 나눕니다. 과거 생성된 내용에 기반하여 비디오를 조각별로 생성합니다.
vanilla next token generation(next token을 확률적으로 예측)
text-conditioned Video2World generation(과거 비디오 기반)
시계열 기반 앞선 토큰을 조건으로 다음 토큰을 예측
실시간 예측에 유리, 토큰 길이를 줄여 추론 지연 최소화
<확산 회귀,diffusion-based WFM>
확산 모델은 어려운 생성 문제를 일련의 노이즈 제거 문제로 생각합니다. 가우시안 노이즈 비디오에서 점진적으로 노이즈를 제거하여 비디오를 생성합니다.
Text2World
Video2World
가우시안 노이즈 점진적으로 제거하며 연속 벡터를 디퓨전 (미래 프레임을 가상의 노이즈에서 복원)
고해상도, 물리 일관성이 중요한 텍스트/영상 생성, 연산량 많음
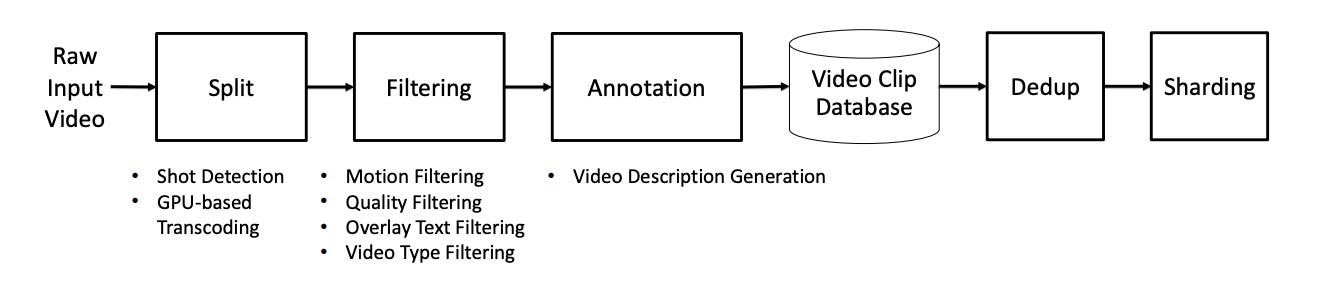
샷 경계 검출 최신 딥러닝 모델은 긴 동영상을 학습하지 못한다. 그래서 의미있는 영상만 클립으로 잘게 쪼개는 작업을 수행하는데, 이때 장면전환 같은 것들이 문제가 될 수 있다. 샷 경계 검출은 고전적인 컴퓨터 비전의 문제로 PySceneDtect와 같은 라이브러리를 활용한다.
비전 기반 학습 데이터 초기 지도학습을 위한 현실 세계의 물리 법칙(중력, 유체역학, 열전달, 관성모멘트 등)을 전부 고려하여 파운데이션 모델을 설계하더라도 세상의 동작방식을 온전히 규정할 수 있을까? 학습데이터가 무엇이냐가 굉장히 중요한 문제일 것, 그런 측면에서 VLM 기반 이미지 학습 방법은 현상을 기반으로 학습하기에 오차율을 줄일 수 있을 것으로 보인다.
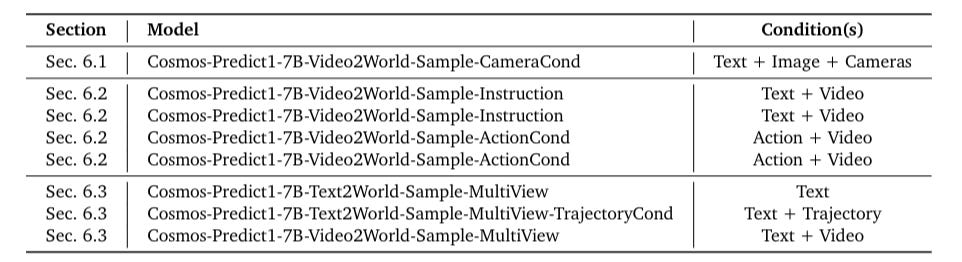
사후 학습(Post Training) 사전 학습 시킨 WFM을 환경에 맞춰 사용자 지정 데이터 세트를 통해 미세 조정합니다. 카메라 제어를 통한 WFM 사후 훈련, 로봇 조작 작업을 위한 WFM 사후 훈련, 자율 주행 에이전트 훈련을 위한 멀티뷰 등 다양한 환경에 맞춰 모델을 버티컬하게 학습시킵니다.
다양한 샘플 모델을 개발자가 선택하여 버티컬하게 사용
프롬프트 기반 미래 video 생성
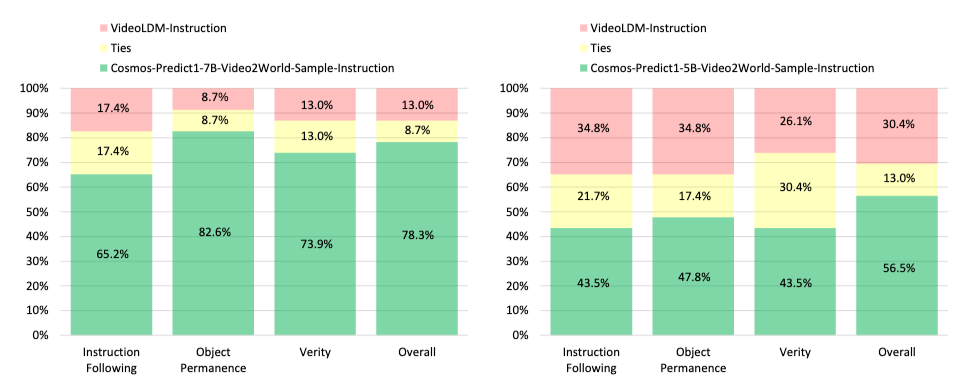
사후 학습을 통해 Fine-tuning 된 Cosmos Predict(초록색)이 더 높은 선호도 평가를 받고 있음
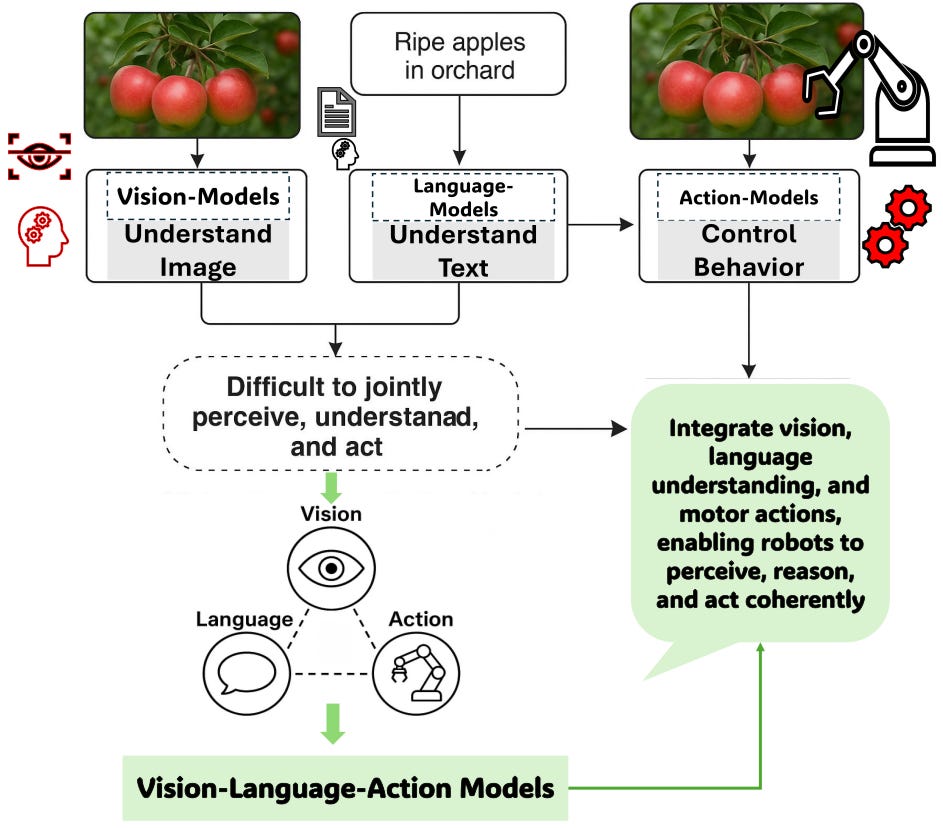
VLA(Vision-Language-Action) 모델
WFM 모델이 세상을 이해하고 예측하기 위해 시각 정보를 바탕으로 학습하는 모델이었다면, VLA(Vision-Language-Action) 로봇이 사람처럼 주변 환경을 인식하고 액션 토큰 또는 연속 제어하여 상황에 맞게 유연한 대응이 가능한 로봇 지능입니다. Figure AI의 Helix를 비롯해 Physical Intelligence의 π0.5, 구글 DeepMind, 테슬라 등의 기업들은 “보고 → 이해하고 → 움직이는” 전 과정을 단일 신경망에 통합해, 다양한 작업을 인간의 언어 지시만으로 즉시 수행 가능한 VLA 모델 개발에 투자하고 있습니다.
1) 환경 인지: 센서 데이터와 디지털 트윈 시뮬레이션
VLA 로봇의 첫 단계는 주변 환경을 인식하는 것입니다. 이를 위해 카메라, LiDAR, 깊이 센서, 마이크 등 다양한 센서로부터 시각·청각 정보를 수집합니다. 예를 들어 Helix와 같은 모델은 로봇의 머리와 손에 장착된 여러 카메라와 깊이 센서로 물체의 위치와 형태를 파악합니다.
2) 의사결정 AI 구조: 거대 멀티모달 모델과 메모리 모듈
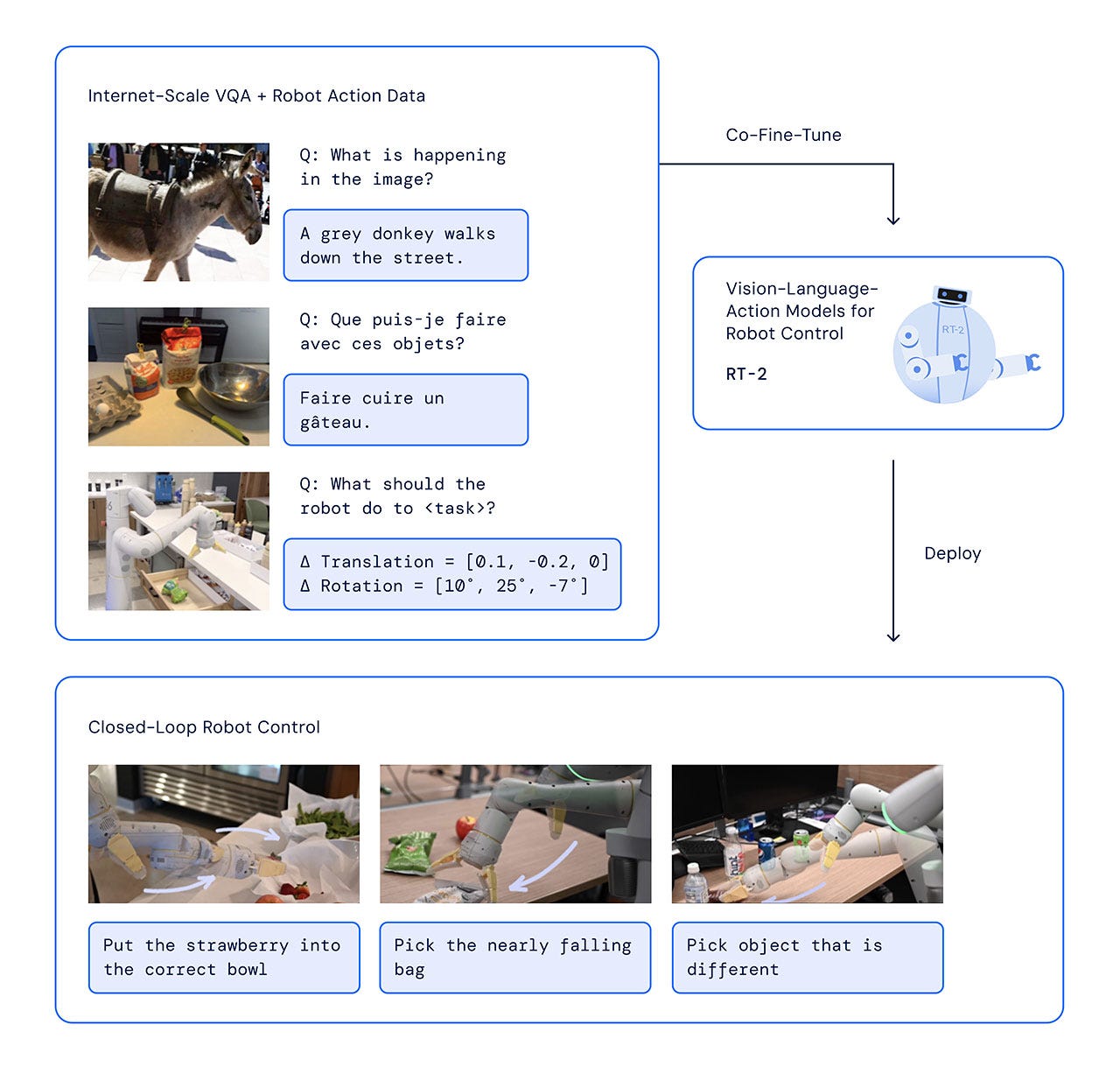
환경을 파악한 로봇은 이후 어떤 행동을 취할지 결정해 줄 AI 두뇌가 필요합니다. VLA 모델의 두뇌는 카메라로 수집한 상황 정보와 인간의 명령어를 입력으로 받아 추론과 계획을 수행하는 대규모 신경망입니다. 이러한 방대한 멀티모달 데이터를 효율적으로 처리하기 위해 주로 Transformer(어텐션)기반 모델이 사용됩니다.
RT-2 참고
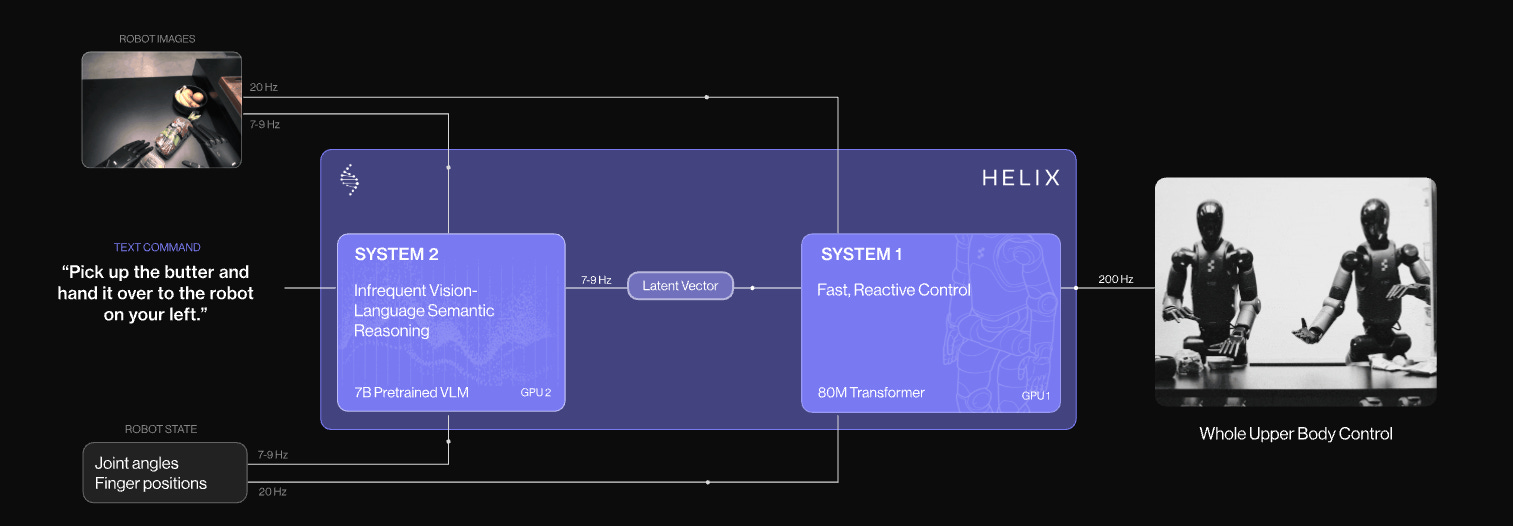
계층적 모듈 구성(이중두뇌) Figure AI의 Helix 모델을 보면, 인간의 두 시스템처럼 System 2(고차원 사고)와 System 1(즉각적 반응) 두 개의 뉴럴넷으로 분리된 아키텍처를 사용합니다.
- System 2(S2): 장면 이해 및 언어 이해를 위해 7~9Hz로 작동하는 온보드 인터넷 사전 훈련된 VLM으로, 객체와 맥락 전반에 걸쳐 광범위한 일반화를 가능하게 합니다.
- System 1(S1): S2가 생성한 잠재적 의미 표현을 200Hz에서 정확하고 연속적인 로봇 동작으로 변환하는 빠른 반응형 시각 운동 정책입니다.
쉽게 말하면, System2가 ‘생각하는 뇌’라면 System1은 ‘반사신경 뇌’에 해당합니다. 이렇게 두 계층으로 나누면, 한쪽은 여유 있게 계획 수립을 하고 다른 한쪽은 실시간 피드백 대응을 함으로써, 복잡한 문제 해결과 빠른 반응성을 모두 잡을 수 있습니다. AI와 인간의 사고체계는 다름지만(확률적 해석) 인간의 사고과정을 모방하였더니 이전보다 정교해졌다는 것은 주목할만한 점입니다.
3) 행동 실행: 액션 토큰과 모터 커맨드 인터페이스
VLA 모델이 무엇을 할지 결정했다면, 이제 로봇의 팔과 다리를 실제로 움직여 결과를 내야 합니다. 이는 곧 추상적인 AI 출력을 물리적 모터 명령으로 변환하는 단계입니다. 전통적으로 로봇 제어는 각 관절의 각도, 속도 등을 지속적으로 조정해야 했다면, VLA 시대에는 이 부분도 학습된 모델의 출력으로 다루어지고 있습니다. 학습 모델의 출력은 두 가지 대표적인 접근방식이 있는데, 하나는 연속 제어 신호 직접 출력, 다른 하나는 디스크리트 토큰 형태로 출력하는 방식입니다.
Figure AI(Helix) vs Google Deepmind & Physical Intelligence(π 0.5) Helix와 같이 고차원 휴머노이드 제어를 지향하는 모델은 액션 토크나이즈 없이 곧바로 연속 제어 신호를 내보내는 경로를 택했습니다. Helix의 System1은 200Hz로 동작하면서 로봇 팔 7자유도, 손가락 10여 개 등 고차원 관절 공간의 모터 명령을 실시간 연속값으로 출력합니다. 반면 Google DeepMind의 RT-2나 Physical Intelligence의 π 0.5는 액션 토큰 개념을 적극적으로 활용합니다.
Helix는 요런 이점이 있다고 함
디지털 트윈기반 시뮬레이션 학습(DT)
현실 세계의 물리적 대상(설비, 건물, 선박 등)이나 프로세스를 디지털 공간에 실시간으로 복제·모델링합니다. 시뮬레이션된 공장, 창고 또는 테스트 환경을 통해 엔지니어는 컴퓨터 비전 모델을 다양한 물체 유형, 조명 조건, 카메라 각도, 날씨 시뮬레이션, 심지어 의도적인 이상 현상까지 수천 가지의 순열에 노출시켜 현실세계에서 실행 불가능 또는 높은 비용의 테스트를 진행할 수 있습니다.
성균관대 - t-ranno 3년 전 들었던 도시공학설계 교수님께서 건물의 화재, 가스 누수 등 전체 시스템 예측 감지를 위한 건물 데이터 수집과 예측 오차율 절감, 도시 인프라 디지털 트윈과 관련된 프로젝트
DT 기반 강화학습/미세조정 (Reinforcement Learning/Fine-tuning)
강화학습은 에이전트가 환경과 상호작용하면서 보상을 최대화하는 행동을 학습하는 방법입니다. Physical AI에서는 실제 생산 환경에서 최적의 제어 전략을 학습하는 데 활용됩니다.
강화학습의 장점은 복잡한 동적 환경에서의 의사결정 최적화입니다. 예를 들어, 로봇이 조립 작업을 수행할 때 부품의 위치나 형태가 조금씩 다를 수 있는데, 강화학습을 통해 다양한 상황에 유연하게 대응하는 전략을 학습할 수 있습니다.
현재 주류 기업들은 시뮬레이션 환경에서 먼저 학습한 후 실제 환경으로 전이하는 방식을 사용합니다. 이는 실제 설비에서 시행착오를 겪으며 학습할 경우 생산 중단이나 설비 손상 위험이 있기 때문입니다. 대표적인 사례로는 공정 파라미터 최적화, 로봇 경로 계획, 생산 스케줄링 등이 있습니다.
조금 쉽게 이해한다면 이런 느낌..?
GAN 기반 데이터 증강
생성자(Generator)와 판별자(Discriminator)가 적대적으로 학습하며 새로운 데이터를 생성하는 방법으로, Physical AI 훈련을 위한 합성 데이터 생성에 광범위하게 활용됩니다. (의료 영상 분야에서는 GAN 기반 합성 데이터 증강을 통해 기존 대비 15-20% 성능 향상을 달성 기록 있음)
미국을 중심으로 한 Physical AI 분야의 주요 기업들을 살펴보면, 혁신적인 스타트업들과 함께 이들을 지원하거나 직접 기술을 개발하는 대기업들이 혼재합니다. 밸류체인 상에 수 많은 연결 관계가 있겠지만, Physical AI를 중심으로 핵심적인 레이어만 나열하였습니다.
Generative Physical AI 밸류체인 분석
노랑: 인프라 & 컴퓨팅 / 핑크: 데이터 & 시뮬레이션 / 초록: 지능 모델 / 그레이: 하드웨어 / 파랑: 시스템 통합 & 운영
❺ NVIDIA’s Physical AI Platforms
NVIDIA는 Physical AI를 학습 모델과 생태계를 제공하고, 이를 기반으로 하는 컴퓨팅 시스템 Blackwell 병렬 컴퓨팅 리소스 및 슈퍼컴퓨팅 솔루션을 판매하며 시장을 장악하고 있습니다. Perception AI, Agentic AI에서 GPU시장을 독점했던 것처럼 Physical AI를 위한 생산 공장과의 파트너쉽(데이터 수집), 데이터센터 구축과 같은 Physical AI 인프라를 위한 선행조건들을 이행하며, 필요한 인프라(Computing Resources) 생태계를 점유하기 위해 앞서나가고 있습니다.
❻ 기술적 의미와 과제: 다시 본질로 돌아가서
AI와 로봇이 왜 만나야 하는가? 현재처럼 다양한 플레이 시퀀스를 정의하고, 그에 맞춰 통합 관리하면 되는거 아닌가? 우리는 본질로 돌아가 AI가 왜 이 로보틱스 산업에 필요한지 이해할 필요가 있습니다. 동시에 이 큰 흐름이 가져오는 변화도 무엇인지 판단해야 합니다.
현재 Agentic AI로 돌아와서 우리가 체감하는 기술적 변화는 무엇일까, ‘생산성’ 그리고 더 실감나는 인간이 처리하지 못하는 병렬적 정보처리 능력(ex: Alphafold) 같은 것들입니다. 생산성에 가치를 상승시켜 기업, 정보를 처리하는 사람들의 속도를 비약적으로 상승시켰습니다. 그리고 생산성의 향상이 기존 노동을 통해 유지하던 노동인력의 생산성을 대체하며 인간의 역할을 대체하려는 흐름을 보이고 있습니다. 산업에서 노동력 대체를 이루기 위해 가장 본질적으로 물어봐야할 것, ‘지금 보다 저렴해?’ , ‘현재 업무를 가져가고 책임져줄 수 있어?, ‘너의 삶의 경험과 지식(모멘텀)을 살 수 있어?’ 더 많은 요소가 있을 수 있겠다만,, 가장 떠오르는 세 가지 비용 효율성과 노동력 분산, 그리고 지식 모멘텀 거래의 이유로 우리는 사람을 고용합니다.
대체의 관점에서 3가지와 더불어 기존 물리세계에 AI가 통합되는 것은 무엇을 의미할까요? 가장 큰 의미에서는 물리세계의 완전 데이터화와 미래예측, 높은 에너지 효율 그로 인한 파생가치들이 아닐까 싶습니다. 산업적 데이터들이 컴퓨터가 이해할 수 있는 또한 인간처럼 판단할 수 있는 자료로 내재화하는 것은 물리세계에 대한 통제권을 갖는다고 볼 수 있습니다.
노동력 분산 : 기업이 성장하고, 의사결정 항목이 다양해지며, 더 많은 업무를 처리하기 위해 우리는 채용을 합니다. 이에 따라 책임도 분산됩니다. 기업 입장에서 책임이 다차원적으로 분산되는 일은 좋은 것일까요. 마치 하청의 하청구조와 같이 리스크와 책임이 분산되는 것은 매니징 리소스가 더 커진다는 의미와 같습니다. 완전 데이터화와 AI 도입은 이러한 책임을 하나의 노드로 모으게 됩니다. 의사결정권자와 시스템 관리자와 같이 복잡한 구성의 책임구조를 단일화하여 기업의 매니징 리소스를 감소시킬 것입니다.
지식 모멘텀 거래 : 중요 인력의 이직과 퇴사는 회사에서 꽤나 중요한 문제입니다. 시스템이 잘 갖추어진 회사더라도 그간 쌓아온 경험과 지식이 휘발돼 버리며, 새로운 사람을 뽑고 온보딩시키는 리스크도 감수해야합니다. 이를 일관된 시스템으로 데이터화하여 사람을 대체하는 것은 지식이 연계되고 온전히 유지된다는 측면에서 비용절감이 일어납니다.
비용 효율성 : 현재 산업이 풀어가고 있는 문제일 것입니다. 현재는 산업구조에 맞춰 도입하는 비용과 레거시 구조를 변경하는 비용이 대체 인력을 사용하는 것보다 훨씬 클 것입니다. 그러나 인력을 대체하므로써 얻는 장기적 효용은 비교할 수 없을만큼 거대합니다. 시간에 관계없이 기업은 원하는 생산량을 조절할 수 있으며, 산업 재해와 같은 리스크를 감수할 필요가 없고, 지식의 모멘텀이 유지되며, 비용차원에서의 효율성을 시스템적으로 컨트롤할 수 있게될 것입니다. 제조업에도 다양한 분야가 있을 것입니다. 고정된 제조 파이프라인의 경우 기존의 시스템을 이용하는게 효율적일 수 있습니다(AI는 변수발생 리스크가 있을 수 있으니..) 그러나 제조업에도 여전히 사람이 하고 있는 일이 훨씬 많습니다. 예를 들어 자동차 조립이라던가,, 생산라인의 이동이라던가,, 등등 다양한 케이스가 있을 수 있습니다. 변화하는 환경에 대응 가능한 범용로봇의 도입은 장기적 효용성을 가져올 수 있습니다. (더불어 생산의 유연성도 ++)
Physical AI의 발전은 단순히 시장의 대체로만 바라보기에는 너무 평면적입니다. 우리가 살아가는 물리세계를 어떻게 이해할 것인가, 컴퓨터가 이해할 수 있는 데이터로 어떻게 전환할 것인가라는 거대한 변화로 바라봐야하며, 한정된 리소스 속에서 우리는 테스트할 수 있는 시간적, 공간적 자유도를 얻을 수 있는 가능태에 대한 탐구하고 있다는데에 더 큰 의미가 있을 것입니다.
거대한 변화 앞에서.. 나는?
반도체, 퍼스널 컴퓨터, 웹, 모바일 그리고 AI 새로운 W를 마주하고 있습니다. 빌 게이츠의 Microsoft(마이크로컴퓨터의 등장과 인터프리터 제작), 제프Amazon(웹을 활용한 디커플링, 월마트와 같은 오프라인 시대의 몰락)과 같은 거대 기업들은 거대한 기술 흐름을 기반으로 생태계를 구축했고 혁신을 이루었으며, 거대 자본은 혁신이 이루어지는 곳으로 밀집될 것입니다.
현재 어플리케이션 레이어에서 서비스의 경쟁은 치열합니다. 모두가 플랫폼, AI 프로덕트를 만들고 있습니다. 장점은 명확합니다. 아이디어 베이스로 빠르게 만들 수 있으며, 시장의 피드백을 얻기 수월하고, 빠른 Growth를 만들 수 있습니다. 반대로 파운데이션을 만드는 비즈니스에 도전하는 기업은 소수 입니다. 거대 기업들이 구축한 해자는 높고 자본의 규모는 아득히 먼 수준의 차이입니다. 우리가 힘들게 만든 모델, 프로젝트도 거대 기업이 삼켜버릴지 모릅니다. 그럼에도 이곳에는 거대한 임팩트를 낼 수 있는,아직 누구도 확언할 수 없는 가장 큰 규모의 기회가 있습니다.
결국 결과론적인 얘기임에도(나에게는 삶의 이야기니까) - 21~24살 현재까지 AI 가상휴먼, 커머스, 뉴스레터, 세일즈, 저작권 등 다양한 도메인에서 크고 작게 서비스를 만들며 고민한 것은 나의 최대 몰입을 이끌기 위해서는 문제에 대한 Alignment가 맞는 팀원들과 우리가 정말 해결하고 싶은 과제에 도전하는 것이다. 5년, 10년이 걸리더라도 99%의 실패 이유가 있더라도 스스로 가스라이팅 할만큼 확신이 있기에 베팅을 걸 것이다. 짧은 시간에 바짝 땡길 수 있는 서비스는 빠르게 회수하기 위해 선택할 수 있지만 지속할 수 없다. 그리고 회수할 시기를 놓쳤을 때, 100% 확률로 우리는 실패할 이유를 찾을 것이다. 그러한 이유로 어차피 힘들거 언섹시해도 상관 없으니 큰 문제에 큰 규모에 도전하고 싶다.
이러한 거대한 변화 속에서 나는 어떻게 시장에 변화를 일으킬 수 있을까.. UNIX와 멀틱스처럼 기술의 본질로 되돌아가 들여다보고 현재 모델이 정말 세상을 관찰하고 예측할 수 있는 최적의 방법인가, 데이터 수집 및 구축은 기업의 Operation Data에 의존해야만 하는가 그렇다면 어떻게 기업의 인프라 데이터를 축적할 수 있을까, B2C 인프라는 어떻게 구성될 수 있을까, IOT 시대에 AI 인텔리전스 인프라가 가구별로 적용된다면 어떤 형태일까, 대규모 데이터 관리는 어떤 방식으로 이루어질 수 있을까, 적재되는 비용과 스토리지 사업은 어떤 방식으로 변화할까 등 수많은 의문이 남아 있습니다. 하나하나 의문점을 풀어가며 조금 더 깊게 Physical AI 분야에 지식을 쌓아올리며 작게 도전하는 것들에 대한 이야기도 담아보려 합니다.